![[Udemy] YOLOv8, Train Custom Dataset, Object Detection, Segmentation, Tracking, Real World 17 + Projects & Web Apps in Python](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FnMyAN%2FbtsC85CoDpx%2F4Nrrkwt9PRePUONZZeji90%2Fimg.png)
반응형
💡 본 문서는 '[Udemy] YOLOv8, Train Custom Dataset, Object Detection, Segmentation, Tracking, Real World 17 + Projects & Web Apps in Python' 강의 내용을 정리해놓은 글입니다.
1. Introduction to YOLO
1) Introduction to YOLO



2) Overview of CNN, RCNN, Fast RCNN, Faster RCNN, Mask R-CNN
Convolutional Neural Network (CNN)
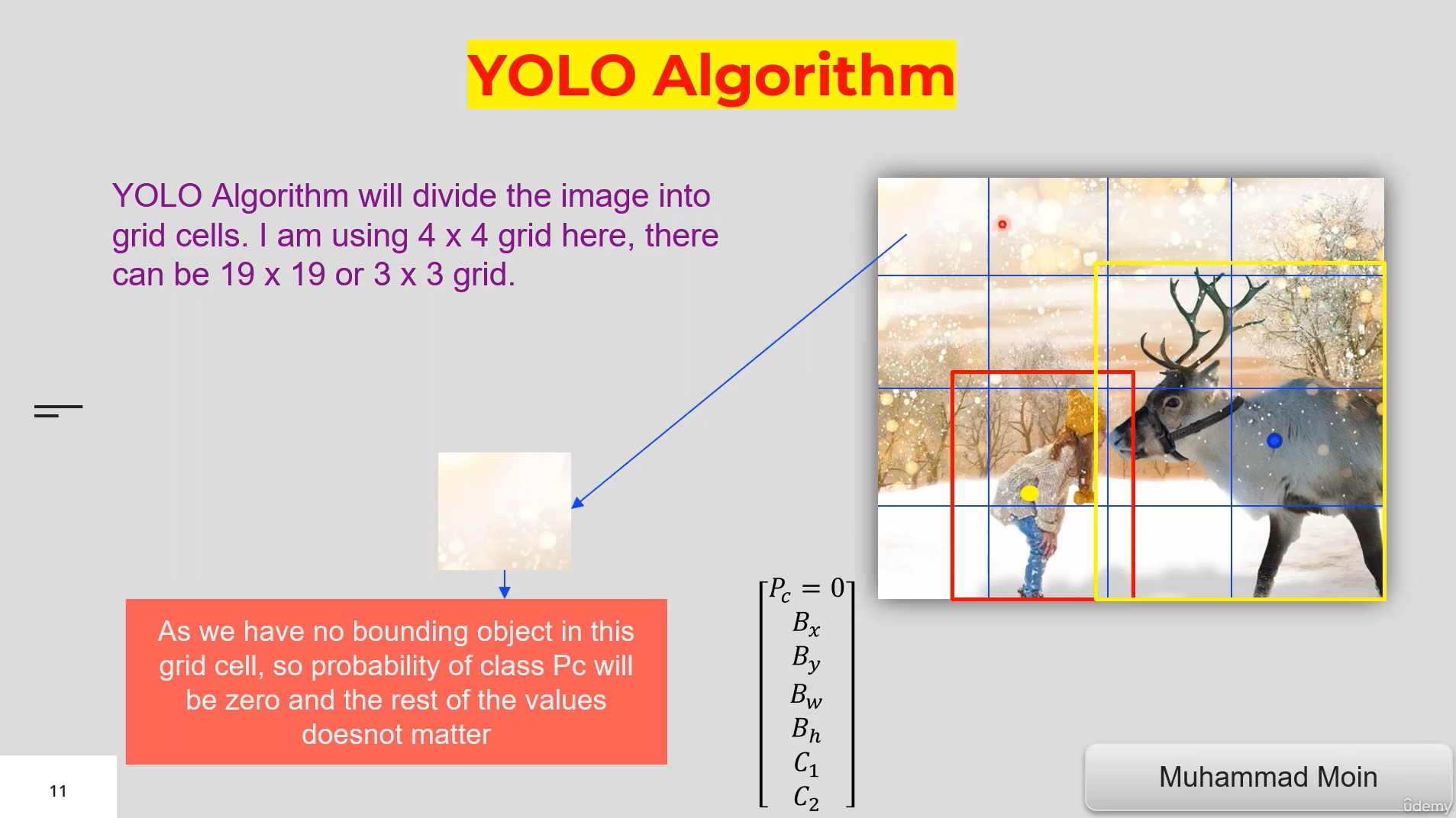
- In object detection, we need to figure out where is the object in the image
- One way to do object detection using CNN is to divide our image into smaller blocks/grids
- We can divide image into 1000 x 1000 of small grids. but it can become computationally expensive.
Region Based CNN(R-CNN)
- The goal of Region Based CNN(R-CNN) is to take an input image and correctly identifying where are the objects in the image via bounding boxes( image into number of boxes instead of grids )
- input: image
- output: Bounding Boxed + Labels for each object in the image
- RCNN uses selective search algorithm to extract 2000 regions from the images called region proposals
- we identity diffenrent regions in the image and then pass them to the feature extractor
- R-CNN Following Steps:
- Generate a set of region proposals using selective search algotirhm for the bounding boxes
- Run the images in the bounding boxes through the pretrained AlexNet
- Finally an SVM to see what object the image has in the bounding box
- Run the bounding box through a Linear Regression model to output detected coordinates for the box
Fast R-CNN
- we send the whole image through the CNN(feature extractor) and then in the feature space we have the Region Proposal
Faster R-CNN
- Faster R-CNN is an object detection algorithm which eliminates the use of Selective Search Algorithm and let the network learn the region proposals(do not use selective search algorithm)
- R-CNN and Fast R-CNN use selective search algorithm to find the region proposals which is slow
- In Faster R-CNN a separate network is used to predict the region proposals instead of selective search algorithm.
- Faster R-CNN gives the bounding boxes only, but no semantic segmentation
Mask R-CNN
- The main idea is extend Faster R-CNN to pixel level segmentation
- In Mask R-CNN a fully convolutional Neural Network is added at the top of CNN features of Faster R-CNN which generates the mask output
- Mask R-CNN uses a trick called ROI Align to locate relevant areas down to pixel level. The baskbone of Mask R-CNN is ResNet101
- Detectron2 is a framework and main model used in Mask R-CNN
3) Introduction to YOLOv8
What is YOLO
- YOLO gained popularity because of its accuracy while maintaining a small model size
- From versions 1-4 YOLO was maintained in a C code in a custom deep learning framework written by Darknet
- In the last two years YOLOR, YOLOX< YOLOv6, YOLOv7 written by Pytorch
What is YOLOv8
- YOLOv8 can be used for object detection, image classification and instance segmentation tasks
- the issue of prolonged training is some whar addressed.
- The trade off between traiing time and precision is achieved more in YOLOv8
Key Features of YOLOv8
- making it easier to switch between different versions and compare their performance
- YOLOv8 includes a new back bone network, a new anchor free detecion head and a new loss function
- YOLOv8 is highly efficient and can run on variety of hardware platforms, from CPU's to GPU's
- Anchor free detections are faster and more accurate than previous versions
4) Comparison of YOLOv8 and YOLOv7 considering the License Plate Detection Problem
How YOLOv8 is Better than Previous Versions of YOLO
- introduces a new backbone network, Darknet-53
- Darknet-53 is a colvolutional neural network that is 53 layers deep and can classify images into 1000 object categories
- YOLOv8 makes bounding box predictions similar to image segmentation (pixel-wise)
- YOLOv8 also uses feature pyramid networks, which helps to better recognize objects of different sizes
Comparison of YOLOv8 with YOLOv7
- Dataset: The dataset had 601 iamges for training and 64 images for validation
- Epochs: The number of epochs were set to 100 to see the performance of YOLOv8 and YOLOv7 model in warm-up iterations
Observations
- The trade-off between training time and precision is achieved more in v8
- New backbone network, a new anchor-free detection head, and a new loss function making things much faster
4. YOLOv8 Object Tracking
Introduction to Multi-Object Tracking
Introduction to Tracking
- Object Tracking is a method to track detected objects throughout the frames using their spatial and temporal features
- tracking can we considered as a two-step process
- we do the detection and localization of the object using any type of object detector it can be either YOLOv7, YOLOR or YOLOv8
- using a motion predictor we predict the future motion of the object using its past information
Types of Tracker
- Single Object Tracker: Track single object
- Multiple Object Tracker: Track multiple objects present in a frame at the same time even of different classes while maintaining high speed
What is DeepSORT
- Computer Vision Tracking Algotithm used to track objects while assigning each of the tracked object a unique id.
- DeepSORT introduces deep learning into SORT algotithm by adding appearance descriptor to reduce the identity switches and hence making the tracking more efficient

Simple Online Real Time Tracking(SORT)
- approach to object tracking where Kalman Filters and Hungarian Algorithms are used to track objects
- SORT consists of four components
- Detection: detection of all the objects which are needed to be tracked is done using YOLO
- Estimation: The detections are passed from the current frame to the next frame to estimate the position of the target in the next frame using Gaussian Distribution and constant velocity model. The estimation is done using the Kalman Filter
- Data Association: a cost matrix is computed as the IoU distance between target bounding box and all predicted bounding box
- Creation and Deletion of Track Identities: When object enters or leave the unique object id's are created and destroyed accordingly
Issues in the SORT Algorithms
- Deficiency in tracking to occlusion/fails in case of occlusion and different view points
- Despite the effectiveness of Kalman filter, it returns a relatively higher number of ID switches
How DeepSORT solves these issues
- These issues are because of the association metric used.
- In DeepSORT another distance metric is introduced based on the appearance of the object. The appearance feature vector (Deep Appearance Descriptor)
- DeepSORT uses a better association metrics which combines both motion and appearance descriptors
- DeepSORT can be defined as a tracking algorithm which tracks object not only based on on the velocity and motion of the object but also based on the appearance of the object.
YOLOv8 Segmentation
1) YOLOv8 Segmentation
- YOLOv8 segmentation model is one of the fastest and most accurate models for real-time instance segmentation
- Instance segmentation goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image
2) Objects Segmentation using YOLOv8
!pip install ultralytics==8.0.0
!yolo task=-segment mode predict model=yolov8s-seg.pt source='image1.jpg'반응형