![[컨퍼런스] 우아한형제들 우아콘 2024 회고: 배달 로봇 dilly (24.10.30.)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FYPBxG%2FbtsKtGXI08U%2FSWK9tyyXvHMnowgyViHNL0%2Fimg.png)

# 주제
한 번의 배달을 위해 필요한 모든 기술들: 우아한 테크콘퍼런스 2024
# KeyPoint

1) 자율주행 로봇을 위한 머신러닝 모델의 추론 성능을 최적화하기
Edge Device는 저전력 고효율이 있는 알고리즘을 사용해야 한다. Edge Device라고 하면 대표적으로 NVIDIA Jetson Nano를 들 수 있는데, 해당 디바이스는 당연히 서버에 비해 낮은 성능을 갖게 된다. 하지만 자율주행을 실행하기 위해서는 필연적으로 10Hz 이상의 주기로 로봇에 요청을 보내야 한다. 이는 인지 판단 제어를 모두 포함한 주기이다. 따라서 인공지능 기술이 매우 고도화되었다고 이를 그냥 사용할 수는 없으며, 최적화를 수행해야 한다. 최적화에는 여러 과정이 포함될 수 있으며, 해당 세션에서는 인퍼런스 속도 최적화에 대해 다루었다.
인퍼런스 속도 최적화하기 위해 사용하는 프레임워크는 대표적으로 NVIDIA TensorRT가 있다. 물론 이는 NVIDIA Embeded 보드에만 적용할 수 있다는 단점이 존재하지만, 해당 보드를 사용한다면 여러 최적화 알고리즘을 간단하게 사용할 수 있도록 제공해주고 있다. 해당 기술을 편하게 사용하기 위해서는 인공지능 알고리즘을 짜는 대표적인 프레임워크인 Pytorch를 공통적인 포맷인 ONNX로 변환하여 이를 최적화하는 방법으로 쉽게 사용할 수 있다. 하지만 이때 Pytorch를 ONNX로 변환하는 과정에서 연산자를 갈아 끼우는 과정에서 오버헤드가 생길 수 있다. 따라서 여러 AI경량화 알고리즘이 존재한다. 해당 세션에서 다룬 내용은 다음의 4가지이다.
- Quantization
- Layer Tenser Fusion
- Kernel Auto Turning
- Deep Learning Accelerator (DLA)
설명해주신 내용을 하나하나 정리해 보도록 하겠다.
1-1) Quantization
Quantization은 Tensor 내부에 FP32 Type으로 저장되어 있는 데이터를 특정 형태(Int8)로 바꿈으로써 계산정확도에서 약간의 손해를 보더라도 속도의 이점을 갖고자 쓰는 방법론이다. 이는 Range Mapping -> Rounding -> Clipping 형태로 진행된다.
Range Mapping은 FP32를 Int8로 변환한다고 하였을 때, 일대일 매핑이 되지 않기에 특정 범위(e.g. [-5, 5])사이의 Floating 데이터를 [-128, 127] 사이로 맵핑 과정이고, Rounding은 반올림이다. 마지막 Clipping은 초기에 [-5, 5] 사이가 아닌 벗어나는 값이 있었을 경우 Range Mapping시 [-128, 127] 사이를 벗어났기에 이를 max값에 맞춰 Cliping 하는 과정이다. 이러한 일반적인 Quantization을 사용할 경우 필연적으로 정확도가 낮아지기에, 이를 개선한 방법론에는 PTQ, QAT가 있다.
Post Training Quantization(PTQ)는 Range Mapping 단계에서 범위를 효과적으로 세팅하여 최적의 범위를 생성하는 방법론으로 정보 손실을 최소화하여 성능 저하가 덜 일어나는 것에 초점을 맞췄다. 실제 이루어지는 방법은 모델의 각 Layer마다 Tensor의 Histogram을 기반으로 최적의 Range를 계산한다. 그리고 Quantization Aware Training(QAT)은 학습하는 과정에서 범위를 Precision 하는 방법으로, Quantize & Dequantize(QDQ)/Fake Quantization 방법론으로 학습한다. Quantization 후 Dequantization 하는 QDQ 과정을 통해 FP32 -> FP32로 변환하는 Fake Quantization과정을 진행하여, 이전의 값과 비교한 오차값을 구하여 Discrete 하게 변환했을 때의 오차를 시뮬레이션하여 Range 범위를 학습한다.
이러한 과정을 수행할 경우 인퍼런스 속도는 동일하게 떨어지지만, 기존의 Quantization 대비 mAP 감소율이 낮아지게 된다. 예를 들어 3D OD Network에 수행한 결과, 기존 Quantization의 경우 mAP가 8%가량 감소한 반면, PTQ는 4% 가량, QAT는 2% 밖에 감소하지 않는 것을 확인할 수 있다.
1-2) Layer Tenser Fusion
Layer Fusion은 수학적으로 결합이 가능한 여러 Operator를 새로운 Operator로 바꾸어 Cuda kernel 호출 횟수를 최소화하는 프로세스이다. 여기서 Cuda kernel은 CUDA로 프로그래밍 언어로 짜여진 GPU에서 실제로 수행되는 함수이다. 예를 들어 Conv, BN이 원래는 각각 CUDA Kernel을 호출하게 되지만, Fusion 적용 후에는 Conv, BN이 합쳐진 Operator로 하나의 CUDA kernel을 호출하게 된다.
Tensor Fusion은 여러 연속된 연산이 수행될 때, 각각의 Layer가 수행된 후 Memory에 저장하여 불러오는 형식으로 구현된다. Tensor Fusion이 적용된 후에는 Layer를 연산한 후 다음 Layer에 전달해주어 Memory의 읽고 쓰기를 최소화한다. 이 역시도 TensorRT에서는 자동으로 최적화시켜 주지만, Optimal 한 결과를 도출해주지는 못한다. 이러한 사례를 Segmentation 모델에서 확인할 수 있었다.
TREx 네트워크 시각화 툴로 확인해본 결과, conv과 conv를 더한 후 BN 과정이 들어가 있어 Fusion 하지 못한 Layer가 존재했다. 따라서 이 네트워크를 Fusion 하기 위해서는 어떻게 바꿀 수 있을까에 대한 고민은 BN의 추론단계에서의 연산에 답이 있었다. BN은 훈련 단계에서는 배치 상태에서 분포를 구해야 하기에 Non-Linear 한데, 추론 단계에서는 저장된 Parameter를 사용하기에 Linear 하다. 따라서 Linear 하기에 각 Conv를 더한 후 BN을 하는 것이 아닌 각 Conv + BN 후에 더하는 연산으로 변경할 수 있다. 따라서 Conv + BN의 새로운 Operator로 만들어 BN Layer를 하나 줄여 CUDA Kernel 호출횟수를 감소시키는 효과를 얻을 수 있었다. 이로 인해 기존의 추론속도보다 16.5%나 감소시킨 0.157ms의 속도로 추론할 수 있었다.
추가로 궁금하여 Nerwork Layer Architecture Visualization 툴에 대해 살펴보았다.
- [Blog] How to Visualize Deep Learning Models(neptune.ai): https://neptune.ai/blog/deep-learning-visualization
- [Blog] Tools-to-Design-or-Visualize-Architecture-of-Neural-Network: https://github.com/ashishpatel26/Tools-to-Design-or-Visualize-Architecture-of-Neural-Network?tab=readme-ov-file
- [Blog] How do you visualize neural network architectures?: https://datascience.stackexchange.com/questions/12851/how-do-you-visualize-neural-network-architectures
1-3) Kernel Auto Turning
GPU는 한 종류만 있는 것이 아닌 여러 종류가 존재한다. TensorRT는 GPU 플렛폼마다 최적화 방법이 다르다는 것을 인지하고 그것에 따른 최적의 커널을 찾는다. 해당 기능이 Kernel Auto Tuning이며, Auto Tuning의 경우 Ganeralize 하게 동작하기에 모든 경우에서 효과적으로 동작하지 않는다. 이 경우 역시 Segmenation Network에서 사례를 찾아볼 수 있었다.
Layer 별로 Latency를 측정해본 결과, Latency가 눈의 띄게 큰 Layer를 찾을 수 있었고 이는 argmax layer였다. argmax layer를 소개하고자 segmentation network부터 설명하자면. segmentation 결과, C x H x W의 tensor를 얻을 수 있다. 이때 H x W는 이미지 사이즈이며, C의 경우 # of Class이다. 이때 각 tensor의 element에는 확률 값이 들어가 있으며, 각 픽셀마다 몇 번째 Index의 class 가 가장 높은 확률 값을 뽑기 위해 Argmax를 사용한다. 따라서 Argmax layer에서는 pixel 간의 연산이 아닌 channel 간의 연산만 존재한다는 것을 알 수 있다. 따라서 C x H x W가 아닌 H x W x C로 변환(transpose)하면 Channel 방향으로 연산 시 연속적인 메모리 접근에 가능해진다. 조금 더 부연설명을 하자면 Pytorch에서는 NCHW 순서로 Dimension을 저장하는데, 이때 Channel 방향으로 이동하기 위해서는 HW만큼의 memory 이동을 해야 한다(이때 N은 Batch이다). 하지만 NCHW가 아닌 NHWC로 변환하게 되면 Channel 방향으로 이동하기 위하 한 칸만 이동하면 된다. 따라서 이렇게 구현할 경우 효율적인 argmax 연산이 가능해지기에, argmax layer를 넣기 전에 transpose를 수행하여 NHWC로 변환하여 효율적으로 계산할 수 있도록 구성하였다.
이를 위해 CUDA Kernel 연산인 nchwTonhwc을 활용해보니 결과가 동일한 것을 확인했고 의아하여 결과를 프로파일링 해보니, transpose 연산이 사라져 있었고 NCHW로 argmax 연산을 수행한 것을 확인하였다. 따라서 CUDA Kernel 연산을 사용하지 않고 Transpose를 수행했더니 예상대로 동작한 것을 확인하였다. 그 결과, 기존 1.897ms를 1.324ms로 약 30%가량 Latency를 감소시킨 것을 확인하였다. 그리고 Layer Tenser Fusion과 Kernel Auto Turning으로 최적화해 본 결과 다음과 같은 결과를 얻었다.
| 기존 | Layer Tenser Fusion + Kernel Auto Turning 적용 | 성능 향상(%) | |
| Latency | 5.438 ms | 4.614 ms | -15.1 |
| Layer | 142 layer | 117 layer | -19.0 |
추가로 앞서 설명한 Quantization의 경우 성능손실이 발생하지만 Layer Tenser Fusion, Kernel Auto Turning는 Kernel 단계에서 최적화를 진행하기에 성능 손실이 발생하지 않는다.
1-4) Deep Learning Accelerator (DLA)
Deep Learning Accelerator (DLA)는 Jetson 플렛폼에서만 사용할 수 있는 NPU(?)와 비슷한 것으로 Image CNN을 전용으로 만들었기에 Image CNN에서만 사용할 수 있지만, GPU 대비 저전력 연산에 강점을 가지고 있습니다. 하지만 호환되는 Layer가 매우 적으며, 사용하기 위해서는 모듈을 DLA로 변환하는 과정이 반드시 필요로 합니다. 변환하는 과정이 필요함에도 왜 굳이 DLA를 사용해야 할까? 는 GPU와의 성능 비교를 통해 확인할 수 있다. Jetson 모델 중 저전력 모델의 경우 Throughput, TOPS와 W [와트] 당 성능에서 매우 좋은 성능을 보이는 것을 확인하였다. 따라서 Jetson 플랫폼을 잘 활용하기 위해서는 DLA로 변환하는 과정이 필요하다.
그래서 최대한 DLA로 변환하는 과정을 통해 성능을 뽑아본 결과, W[와트] 당 성능이 40%가량 상승하는 것을 확인할 수 있었다. 따라서 최대한 많은 부분을 변환하는 과정을 진행 중이라고 하셨다. 물론 DLA로의 변환하는 비용 자체도 무시할 수 없기에 이를 고려하여 진행해야 한다고 하셨다. 세션 후 네트워킹 시간에 뉴빌리티 관계자 분들이 여러 질문을 해주셔서 추가적으로 파악할 수 있었다.
추가로 NVIDIA 플렛폼이 CUDA 기반으로 생태계를 구축해 놓은 것은 알았지만, 생각보다 활용하기 좋은 SW가 많다는 생각에 조금 더 찾아본 결과 NSight라는 생태계로 활용하기 좋은 소프트웨어가 많았다.
- [NVIDIA] NVIDIA Nsight Developer Tools: https://developer.nvidia.com/tools-overview
- [NVIDIA] NVIDIA Nsight Systems: https://developer.nvidia.com/nsight-systems
2) 자율주행 로봇을 위한 위치 인식 및 동작 계획 기술
자율주행이 실제로 동작하기 위해서는 여러 Task의 상호작용으로 동작하게 된다. 이런 Task에는 대표적으로 Perception, Localization, Motion Control, Task & Motion Planning 등이 있다. 앞 세션에서 언급한 경량화는 모든 알고리즘에서 사용할 수는 있지만, 위의 세션에서는 Perception 중 Segmentation 기술에 적용한 사례를 예시로 들면서 설명해 주셨다.
이후의 세션에서는 여러 Task 중 Localization, Task & Motion Planning에 대해 들었다. 여기서 Localization은 대체로 SLAM이라는 지도를 Mapping 하고, 자신의 위치를 파악(Localization)하는 기술을 주로 사용한다. 또한 Motion Planning에서는 인식한 것을 바탕으로 자신의 위치를 파악한 후 이어지는 Task로 어떤 식으로 경로를 주행할지를 경로계획을 하는 영역이다. 해당 Task에 대해 세션에서 말해주신 내용들을 아래의 내용에서 정리하였으니, 참고하기 바란다.
(기존 아는 내용에 대해서는 많이 정리하지는 못하였으나, 향후 녹화 영상을 제공해 주신다면 사진을 기반으로 조금 더 내용을 추가할 예정이다.)
2-1) 위치 인식 기술
주변 환경 인식에는 GPS, LiDAR, Camera, Wheel Encoder 등 여러 센서가 사용된다. 이때 Localization을 위해서는 GPS기반으로 한다고 흔하게 생각할 수 있겠지만, GPS 기반의 경우 오차가 큰 편이다. 따라서 Mapping 된 지도를 기반으로 자신의 위치를 추정하는 SLAM 기술을 사용하고 한다. 이때 LiDAR센서로 맵핑된 Pointcloud 지도를 사용하게 되면 0.2m가량으로 오차 수준이 감소하게 된다. 기본적으로는 이러한 SLAM 기술을 활용하도록 구성하였으며, 해당 세션에서 다룬 추가로 언급한 테크닉(?)들은 아래의 세 가지였다.
- Relocalizer: 기본적으로 GPS 기반으로 지도상 Search Space를 줄인 후, 한정된 곳에서 Matching을 하기 된다. 이때 관련 논문이 정말 많이 나오고 있는데, Feature, Grid, Branch-and-Bound(BnB) 등 여러 알고리즘을 다 같이 사용한다.
- Submap Manager: 대규모의 지도를 일정 간격으로 나누고 현재의 위치와 가까운 것들만 사용한다. 기본적으로 보드 내 전체 경로를 다운로드하여 놓은 후에 가까운 위치의 지도들은 Memory에 올려서 사용하게 된다.
- Localizability Estimator: 위치 추정 실패를 감지하는 알고리즘이다. Odometry의 결과로 사용할 수 있는 Metric 정해서 사용하며, Decision Boundary를 정해서 감지하는 방식이다.
2-2) 동작 계획 기술
쉽게 설명하면 로봇이 가야 할 경로를 생성하는 과정이다. 이는 이미 알려진 설루션이 많이에 적용하면 되겠지? 하고 단순하게 생각하는 사람들이 많다(아마 개발자보다는 기획 쪽에서 그러지 않을까...). 맞는 말이지만 이를 배달로봇에 적용한다는 것은 또 다른 문제이다. 적용 과정에서 쉬운 점과 어려운 점을 몇 가지 뽑아보면 다음과 같다.
- 문제의 쉬운 점
- 주행 속도: 15km 이하
- 교통, 인도, 차량과의 상호작용이 덜 복잡함
- 문제의 어려운 점
- 리소스(HW, SW) 등의 제약이 큼
- 사회적 인식을 갖춘 행동이 요구됨(Social Aware Motion Planning)
그리고 이러한 Planning 기술 중 단순히 하나의 알고리즘을 사용하여 동작하도록 구성하는 것이 아니라 상황에 따라 취사선택하여 구성해야 한다. 이때 여러 Planner를 설정해 놓은 후 상황에 따라 특정 플래너를 사용하도록 구성하는 것은 행동 플래너를 사용하게 된다. 이를 그림으로 그려보면 다음과 같다.
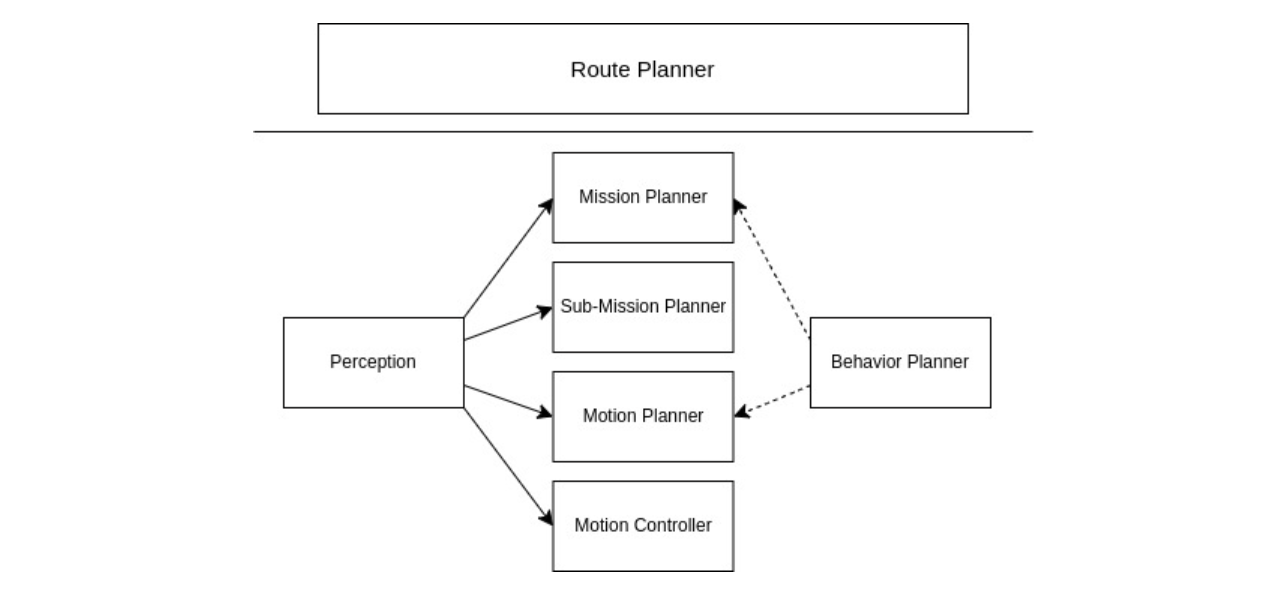
여기서 Mission Planner는 정지해야 하는 공간을 기준으로 Route Planner의 결과를 쪼갠 것이며, Sub-Mission Planner의 경우 Sub-Map Manager에서 관리하는 Sub Map 수준으로 모션을 제어하는 플래너이다.
이러한 모션 플래닝 기술은 크게 Optimization 기반과 Learning 기반으로 나눌 수 있으며, 이들을 또 Sampling based(e.g. Informed-), Search/Grid based(e.g. A*), Reaction based(e.g. DWA)로 나눌 수 있다. 대체로 플래닝은 각각의 알고리즘의 장단점을 기반으로 하나의 알고리즘을 선택해서 주행하는 것이 아닌 상황에 따라 선택하게 된다. 예를 들어, 짧은 경로를 사용하기 위해서는 Reaction based로 연산량을 감소시킬 수 있으나, 여러 예측 경로를 바탕으로 파악해야 하는 경우에는 horizon이 긴 다른 알고리즘을 사용하여 조금 더 예측 범위를 넓히는 방식으로 선정하곤 한다.
해당 세션에서는 최적화 기반의 약점인 Local Optimization을 극복해야 한다고 소개하면서 앞으로 풀어야 할 문제들에 대해서 많이 언급해 주셨다.




# 느낀 점
역시나 이번에도 우아콘은 뜨거웠다. 몇백 명의 랜덤 선발된 인원들만 듣는 것이기에 당연히 열심히 듣겠지라고 생각할 수 있겠지만, 올 때마다 깜짝 놀란다. 이번에 그런 건지 세션별로 입장할 때 줄 서서 기다리는 사람들이 복도를 꽉 채웠다. 정말 '네카라쿠배'라는 명성(?)에 맞게 '배달의민족' 기업 자체에 관심을 갖고 참여하는 사람도 있겠지만, 참여한 모든 사람들이 기술 자체에 열정을 갖고 공부를 하고 있다는 생각이 들었다.
작년에는 배달의 민족 대회를 참여하여 초청받아 참여했었는데, 이번에는 추첨에 당첨되어서 참여하게 되었다. 작년에 비해 올해는 로봇 세션이 얼마 없어서 아쉬웠으나, 있는 2개의 세션 모두 너무 만족스러웠다. 기술 자체가 많이 고도화되었다는 생각이 들기도 하였지만, AI 자체를 계속 공부하고 있는 입장에서 모두 관심이 가는 주제였다.
첫 번째 세션의 경량화 기술에서는 최근에 VirConv라는 CVPR 2023에 나온 알고리즘을 경량화하는 과정에서 위의 경량화 방법론들을 포함하여 Distillation, Prunning 등을 진행해 본 적이 있는데, 이를 다시 복습하는 시간을 가진 것 같고 현업에서 사용되는 스킬들을 배우며 많이 성장하는 시간이었다.
또한 두 번째 세션의 SLAM 기술에 대해서는 3학년 때 많이 관심이 있어서 Spatial AI에서 활동 중인 장형기 님이 번역하신 'Visual SLAM' 책을 살짝 읽어보면서 관심을 가진 적이 있는데, SLAM에 대해 간단히 다룬 후에 Relocalizer, Submap Manager, Localizability Estimator 등 실제 프렉티컬하게 적용하는 과정에서 사용했던 방법들을 언급해 주신 것 같다. 이전에 활동했던 AuTURBO라는 로봇 사회인 동아리에서 배달의민족-모라이 시뮬레이터 대회를 나가며 SLAM 알고리즘을 내재화해본 것으로 알고 있는데, 관련 내용에 대해 언 지를 드리면 살짝은 도움이 되지 않을까 싶다.
마지막으로 두 번째 세션의 동작 계획 기술에 대해서는 최근에 모두의 연구소 Planning 팀에서 논문을 작업하면서 살짝 다뤄본 적이 있었기에 관심을 가지고 들었다. 논문에서 작업했던 것은 Traditional 한 알고리즘을 정보이론으로 조합하여 최적의 알고리즘을 찾아보는 것이었는데, 이전에는 이런 세션을 들으면 하나도 알아듣지 못했는데 위의 논문 작업 덕에 조금은 이해할 수 있었지 않았나 싶다. 이 세션에서 신기했던(?) 점은 단순 루트플래너, 모션플래너로 되어 있는 것이 아닌 미션, 서브미션 단계로 쪼개서 조금 더 프렉티컬 하게 사용한다는 점이었다. 이런 알고리즘을 현업에서 어떤 식으로 사용할까? 조금만 고민했다면 신기하지는 않았을 텐데, 연구를 하면서도 이런 점들을 고민하는 시간을 종종 가져야겠다. 또한 Optimization 방식뿐만이 아닌 Learning 기반 방법들에 대해서도 한번 살펴보고 싶다는 생각을 했다.
정리를 하다 보니 생각보다 너무 길어졌지만, 그만큼 많이 유익했던 시간이었다. 이번에 갔다 와서 가짜연구소 디스코드를 확인해 보니 찬란님께서도 다녀왔다고 하던데, 이번 기회에 한번 뵐 수 있었는데, 다음번에는 조금 더 네트워킹하는 시간도 가지면서 콘퍼런스를 즐겨야겠다.
# 참고
WOOWACON 2024: https://2024.woowacon.com/sessions/