![[LW] 네트워크 경량화: Knowledge Distillation 다양한 방법들(feat. RepDistiller)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FDgTmZ%2FbtsGYfaE1b1%2FAAAAAAAAAAAAAAAAAAAAABI9Dkbitvb29ad8MXKHUgejvNOhW6zI_9J33IIIp9MW%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1767193199%26allow_ip%3D%26allow_referer%3D%26signature%3DIs6Intk9bRSGWd3XfA3UVSn9wJ8%253D)
💡 본 문서는 '[DL] Knowledge Distillation 다양한 방법들(feat. RepDistiller)'에 대해 정리해놓은 글입니다.
Knowledge Distillation은 2014년에 제시된 방법론으로 딥러닝 분야치고는 꽤나 오래된 방법론이지만, 현재까지도 모델을 경량화하는데 많이 사용되고 있습니다. 이 Knowledge Distillation에서 파생된 방법론들에 대해 코드레벨로 정리하였으니 참고하시기 바랍니다.
1. Knowledge Distillation?
Knowledge Distillation 이란?
딥러닝에서 Knowledge Distillation은 큰 모델(Teacher Network)로부터 증류한 지식을 작은 모델(Student Network)로 transfer하는 일련의 과정이라고 할 수 있습니다.
그렇다면 왜 Knowledge Distillation?
지식 증류를 처음으로 소개한 논문인 "Distilling the Knowledge in a Neural Network(Hinton)"은 모델 배포(model deployment) 측면에서 지식 증류의 필요성을 찾고 있습니다. 그렇다면 다음의 두 모델이 있다면 어떤 모델을 사용하는 게 적합할까요?
- 복잡한 모델 T : 예측 정확도 99% + 예측 소요 시간 3시간
- 단순한 모델 S : 예측 정확도 90% + 예측 소요 시간 3분
어떤 서비스냐에 따라 다를 수 있겠지만, 배포 관점에서는 단순한 모델 S가 조금 더 적합한 것으로 보입니다. 그렇다면, 복잡한 모델 T와 단순한 모델 S를 잘 활용하는 방법도 있지 않을까요? 바로 여기서 탄생한 개념이 지식 증류(Knowledge Distillation)입니다. 특히, 복잡한 모델이 학습한 generalization 능력을 단순한 모델 S에 전달(transfer)해주는 것을 말합니다.
Knowledge Distillation 대략적 이해
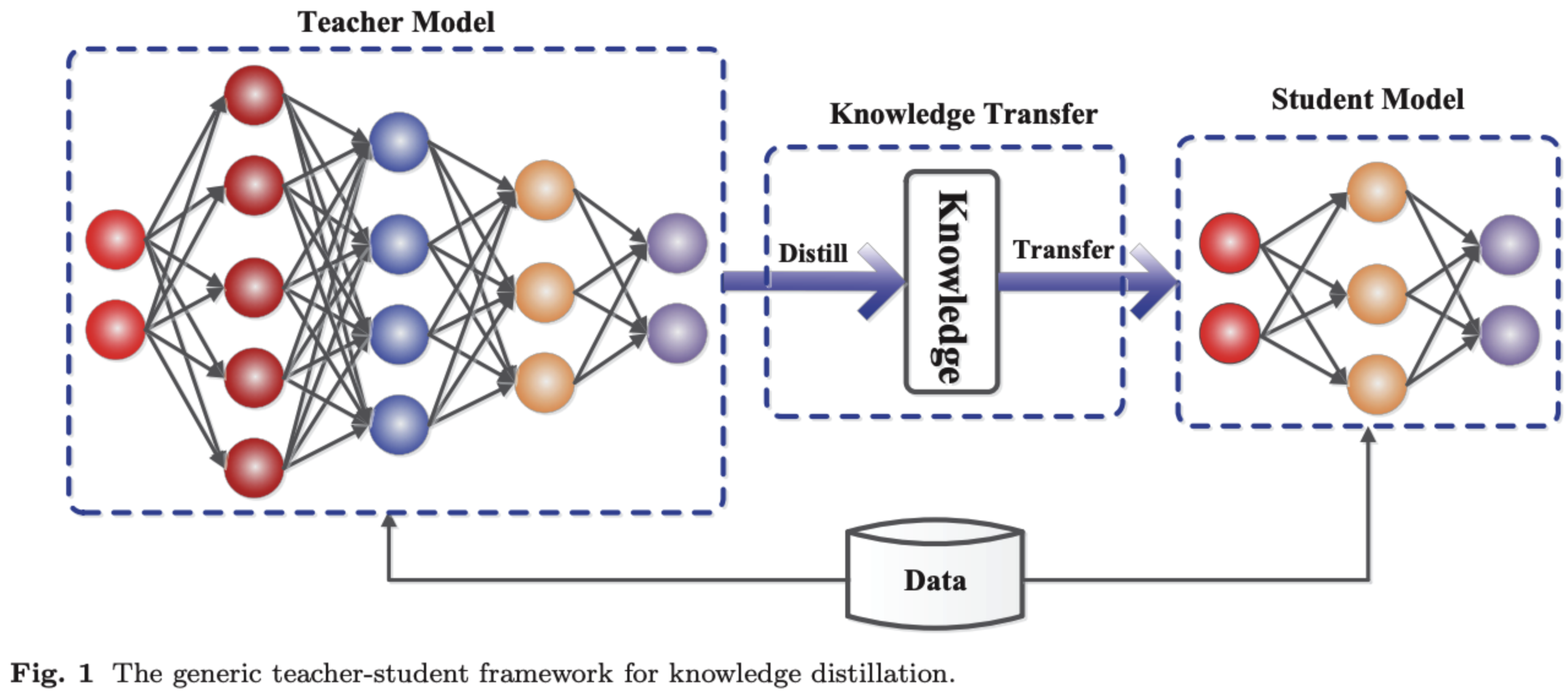
Teacher Network(T): cumbersome model
- (pros) excellent performance
- (cons) computationally espansive
- can not be deployed when limited environments
Student Network(S): Small Model
- (pros) fast inference
- (cons) lower performance than T
- suitable for deployment
Knowledge Distillation 구체적인 방법론 (Sotf Label, KD Loss)
그렇다면 어떻게 큰 모델로부터 작은 모델로 지식을 전달할 수 있는 걸까요? 이는 신경망과 손실함수를 살펴보면 쉽게 이해할 수 있습니다. 앞서 언급한 Knowledge Distillation을 처음 제시한 Hinton의 논문에서 나온 Hinton's KD를 기반으로 살펴보도록 하겠습니다.
1) Sotf Label
일반적으로, 이미지 클래스 분류와 같은 task는 신경망의 마지막 softmax 레이어를 통해 각 클래스의 확률값을 뱉어내게 됩니다. softmax 수식을 통해 다음과 같이 번째 클래스에 대한 확률값()를 만들어내는 방식입니다.

이때, Hinton은 예측한 클래스 이외의 값을 주의 깊게 보았습니다. 개를 제외한 고양이나 자동차 그리고 젖소의 확률을 보았으며, 이 출력값들이 모델의 지식이 될 수 있다고 말하고 있습니다. 하지만, 이러한 값들은 softmax에 의해 너무 작아 모델에 반영하기 쉽지 않을 수 있습니다.
따라서 다음과 같이 출력값의 분포를 좀 더 soft하게 만들면, 이 값들이 모델이 가진 지식이라고도 볼 수 있을 듯 합니다. 이것이 바로 Knowledge Distillation의 시초(Hinton’s KD)입니다. 그리고 해당 논문에서는 이러한 soft output을 dark knowledge라고 표현하고 있습니다.

이렇게 soft하게 만들어주는 과정을 수식으로 표현하면, 아래와 같습니다. 기존 softmax 함수에 T(temperature) 값을 분모로 넣어주어 분포를 soft하게 만들어주게 됩니다.
$$ qi = \frac{exp(z_i)}{\sum_j exp(z_j)} \to qi = \frac{exp(z_i / T)}{\sum_j exp(z_j/T)} $$
2) distillation loss
위에서 정의한 Hinton의 soft target은 결국 큰 모델(T)의 지식을 의미합니다. 그렇다면 이 지식을 어떻게 작은 모델(S)에게 넘길 수 있을까요? 먼저, 큰 모델(T)을 학습을 시킨 후 작은 모델(S)을 다음과 같은 손실함수를 통해 학습시킵니다.

$$ L = \sum_{(x, y)\in D} L_{KD}(S(x, \Theta_S, \tau ), T(x, \Theta_T, \tau )) + \lambda L_{CE}(\hat{y}_S, y) $$
- Student model, Teacher model
- 하나의 이미지와 그 레이블
- 모델의 학습 파라미터
- temperature
는 잘 학습된 Teacher model의 soft labels와 Student model의 soft predictions를 비교하여 손실함수를 구성합니다. 이때, 온도()는 동일하게 설정하고 Cross Entropy Loss를 사용합니다.
2. Knowledge Distillation Schema

Offline Distillation
초기 knowledge distillation은 pre-trained teacher model의 teacher knowledge를 student model로 transffered함.
따라서 2가지 stage의 training 프로세스가 있음.
- 1) distillation 전에 large teacher model을 먼저 훈련함
- 2) 앞서 언급했듯 teacher model의 logits이나 intermediate features를 knowledge로 추출하여 student model의 distillation 훈련시 가이드로 사용함
Online Distillation
In online distillation, both the teacher model and the student model are updated simultaneously, and the whole knowledge distillation framework is end-to-end trainable.
Self Distaillation
In self-distillation, the same networks are used for the teacher and the student models.
(self-distillation means student learn knowledge by oneself)
3. Knowledge Distillation 다양한 방법론 (Algorithms)
참고
- [Paper] Distailling the knowledge in a Neural Network: https://arxiv.org/pdf/1503.02531
- [Paper] Knowledge Distillation: A Survey: https://arxiv.org/pdf/2006.05525
- [Blog] 딥러닝 모델 지식의 증류기법, Knowledge Distillation: https://baeseongsu.github.io/posts/knowledge-distillation/
'Study: Artificial Intelligence(AI) > AI: Light Weight(LW)' 카테고리의 다른 글
| [LW] 네트워크 경량화: Quantization 다양한 방법들 (0) | 2024.05.15 |
|---|---|
| [LW] 네트워크 경량화: Pruning 다양한 방법들 (0) | 2024.05.11 |