![[Vision] CNN Network 기본 모델 정리 (LeNet-5 부터 ResNet 까지)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FJYE1B%2FbtsEm61hwqj%2Fa19eWCmkFqkCfqDkoyGyT0%2Fimg.png)
💡 본 문서는 '[Perception] CNN Network의 역사 (LeNet-5 부터 ResNet 까지)'에 대해 정리해놓은 글입니다.
최근에 나오는 대부분의 모델이 아직까지 ResNet으로 pretrained 된 모델을 사용하고 있다는 점에서 의아하여, ResNet 구조를 공부하고자 이전부터 ResNet까지의 CNN Nerwork의 역사를 정리하였으니 참고하시기 바랍니다.
0. Multi Layer Perceptron (MLP)
Multi Layer Perceptron은 다음과 같은 Layer 층으로 구성되어 있습니다.
- Fully Connected Layer: 입력층과 출력노드를 모두 연결한다.
- Batch Normalization: 각 층의 입력 데이터 분포를 일정하게 유지시킨다.
- Activation Function: 비선형성을 도입하여 특징을 추출한다.
이러한 MLP를 사용하지 않는 이유는 입력층과 출력층이 모두 연결되어있어, 많은 연산을 필요로 하며 과적함되기 쉽다. 이에 반하여 CNN은 다음과 같은 특징을 통해 파라미터 수를 감소하고 패턴을 학습 가능하다.
- Weight Sharing: 같은 커널로 가중치를 공유하며, 가중치의 개수를 줄인다.
- Multiple Input Channel: 여러 필터에서 특징 추출이 가능하다.
위와 같은 Convolution Layer를 통해서 Feature Extraction(특징 추출) 과정을 진행하고 이후 Classification(분류) 과정을 진행한다. Classification의 input은 Feature Extraction Layer를 통과한 Flattened하여 vector화한 후 Fully Connected Layer를 통과한다. 이때 마지막에 출력한 Output Logit 값을 Softmax를 통해 어떤 클래스의 확률이 높은지를 판별하여 클래스를 예측한다.
위의 내용을 기반으로한 CNN의 다양한 모델들이 출범하였으며, 그 변화과정을 설명하도록 하겠다.
1. LeNet-5 (1998)
의의: Convolutional layer와 pooling의 조합을 반복하는 현대적인 CNN 구조를 제안했다는 점에서 의미

- Convolution layer(C), sub-sampling(S), Fully-connected layer(F)
- Convolution Layer: 지역적인 특징 추출
- Sub-sampling(Average Pooling): 이미지 사이즈 감소 -> 위치 이동, 회전 및 부분적인 변화와 왜곡에 강인하도록
- C3에서 16개의 채널을 생성할때 앞 layer의 일부만 선별하여 추출함
- Fully-connected layer + activation(tanh)
- 뒤에 붙는 숫자는 전체 구조에서 몇 번째 layer인지를 의미
2. AlexNet (2012)
의의: 사람이 설계한 feature가 아닌 학습을 통해 선택된 feature를 활용해 기존보다 좋은 성능

- Convolutional layer, Max Pooling, Fully-connected layer
- Multi-GPU 사용: Network를 두 개의 GPU로 나눌 수 있는 구조로 설계
- ReLU사용: Tanh -> ReLU. 학습속도가 7배 빨라짐. saturation 방지.
- LRN(Local Response Normalization): kenel의 한 점에서 공간적으로 같은 위치에 있는 다른 channel의 값들을 square-sum하여 하나의 filter에서만 과도한 활성화 값이 나오는 것을 막는 역할
- Overlapped max pooling: Strid가 kernel(receptive field) 크기보다 작게.
- Data Augmentation: 데이터 증강. Overfitting 방지.
- 1. 256x256 크기의 원래 이미지로 부터 224x224 크기의 이미지를 무작위로 추출
- 2. 수평반전과 RGB컬러성분 변경
- Dropout: 학습할 때 일부 뉴런을 생략. Overfitting 방지.
3. VGGNet (2014)
의의: 망 깊이(depth)가 네트워크 성능에 주는 영향에 대해 확인하기 위한 네트워크
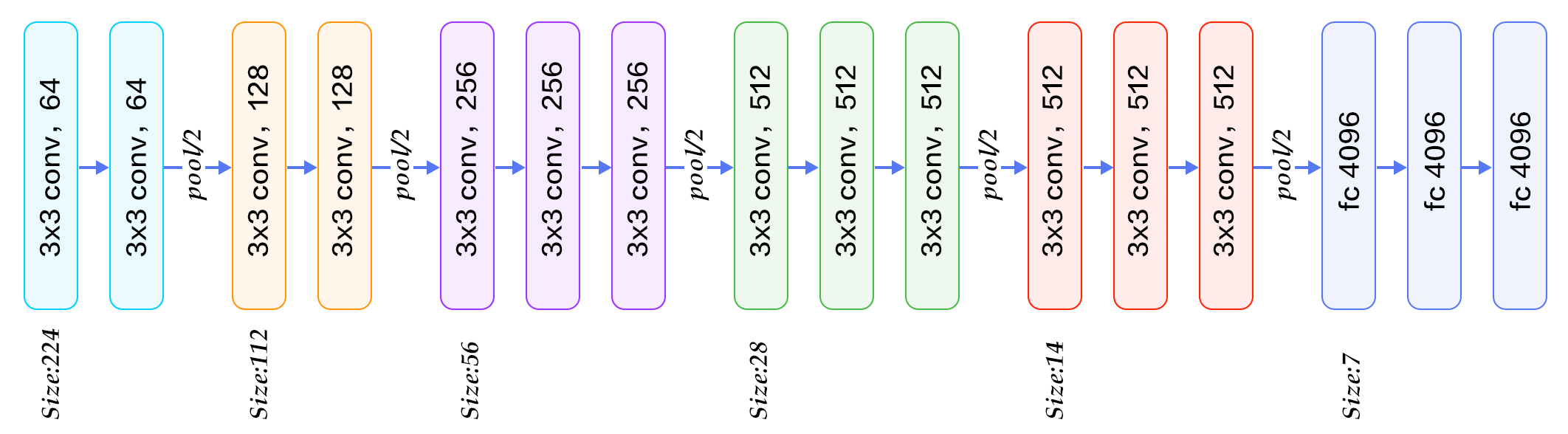
- Convolutional layer, Max Pooling, Fully-connected layer, ReLU, Dropout
- 기본 구조는 Conv layer뒤에 max-pooling으로 해상도를 줄여가는 단순한 구조
- Factoring Conv: kernel 사이즈가 5x5인 convolution은 2개의 3x3 convolution으로 분해(Factoring)
- 비선형성(non-linearity)가 더 증가하여 더 좋은 차별성(구별력)을 가진 feature를 뽑아냄
- 사용하는 파라미터의 수가 줄어들고, 학습 속도가 빨라짐
- Data augmentation: 데이터 증강. Overfitting 방지.
- scale jittering: 다양한 크기의 이미지 데이터들을 동일한 크기로 맞춰서 input size를 단일화시키기 위해 이미지의 크기를 조정하거나 잘라내는 방법
- 수평반전, RGB컬러성분 변경
4. GoogLeNet (2014)
의의: Inception module을 활용해 AlexNet보다 더 깊지만 파라미터 수는 1/12이며, 성능면에서 좋음
GoogLeNet-V1
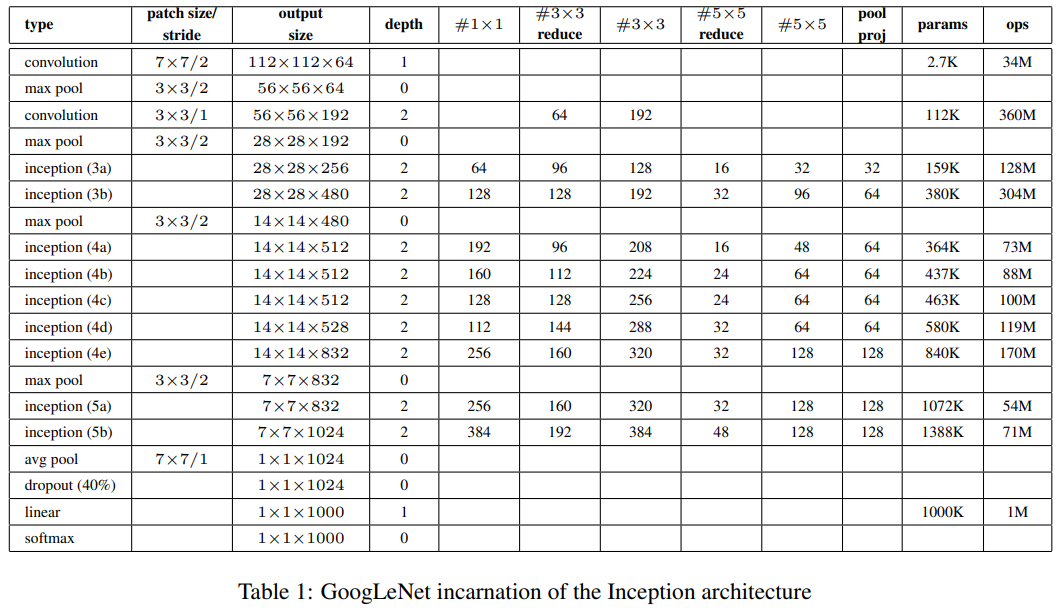
제안 배경
- 딥러닝 네트워크 성능을 높이기 위해서는 네트워크의 크기, 즉 Depth(layer 수)와 width(channel 수)를 늘려야 한다.
- 기존의 Dense한 구조(weight들의 대부분이 0이 아닌 값을 갖는 형태)에서 크기를 키우면 overfitting, 연산량 증가 등 문제가 발생한다.
- GoogLeNet에서는 깊은 망을 설계하되 파라미터 수를 줄이기 위해 dense한 구조 대신 sparse(weight의 대부분이 0인 형태)하면서 크기가 큰 구조로 만든다.
- 그런데 Sparse한 구조는 컴퓨터 연산구조상 효율이 떨어진다.
- Sparse한 구조들 중 상관도가 높은것들을 clustering하여 유사 dense한 형태를 만든다(sparse한 구조들을 묶어 desne한 형태로 만들기)
Inception module
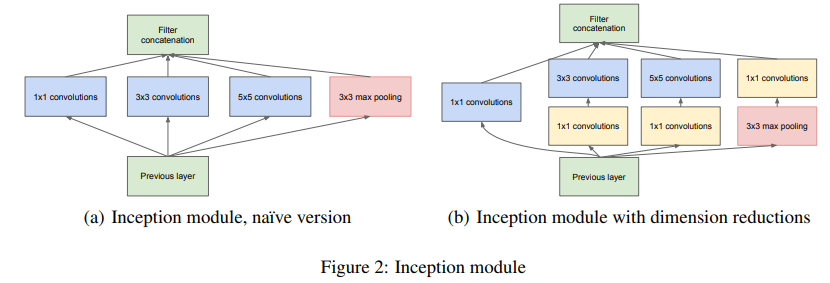
- Multi Scale Conv layer의 병렬 사용: 1x1, 3x3, 5x5 세 개의 Conv layer와 1개의 3x3 Max-pooling을 사용
- 여러 스케일의 Convolution 연산을 활용해 다양한 스케일에서 효율적으로 특징을 뽑아낸 뒤 ReLU함수를 사용
- Convolution network(feature 추출)를 최적의 sparse한 matrix를 만들고, 행렬 연산에서는 이들을 합쳐(concat) 최대한 dense하게 만드는 것
- 이 구조에서 마지막 layer와 상관도 통계분석을 활용해 상관도가 높은(correlation 값이 높은) unit을 clustering
- 1x1 Conv layer 사용: 차원을 축소(dimension reduction)하여 연산량을 줄여주는 역할
- 1. channel 수 조정, 2. 계산량 감소, 3. 비선형성(ReLU)
- unit이 단일 지역에 밀집된 경우는 1x1 Conv layer로 대응이 가능하며, 여러 스케일에서 feature를 동시에 추출함으로 써 feature를 효과적으로 추출
- 단, 1x1로 차원의 수를 줄인 경우 feature가 가지고 있는 정보가 압축되면서 원래의 (a)구조보다 성능이 떨어질 수 있기에, 연산량이 클 때만 (b) 구조를 사용
- auxiliary classifier: softmax를 통해 결과를 뽑아내는 부분이 맨 끝에만 있는 것이 아니라, 중간 중간에 있음
- 이렇게 auxiliary classifier를 덧붙이면, Loss를 맨 끝뿐만 아니라 중간 중간에서 구하기 때문에 gradient가 적절하게 역전파되어 Vanishing Gradient를 방지
- 대신 이 auxiliary classifier가 지나치게 영향을 주는 것을 막기 위해 0.3을 곱하여 사용
- global average pooling: Fully Connected(FC) 방식 대신에 global average pooling이란 방식을 사용
- 전 층에서 산출된 특성맵들을 각각 평균낸 것을 이어서 1차원 벡터를 만들어주는 것
- 1차원 벡터를 만들어줘야 최종적으로 이미지 분류를 위한 softmax 층을 연결 가능.
GoogLeNet-2
- 입력 이미지 해상도 증가: 224x224에서 299x299로 증가
- 3x3 Conv 필터 사용: 제알 앞단의 7x7 Conv layer를 3개의 3x3 Conv layer로 분해한 multi-layer로 구조개선
- Factorization 사용: Inception module도 factorizing convolution된 형태로 치환하여 더 깊되 연산량은 적도록 개선
- Factorization: 일반적으로 n x n 의 형태로 Conv 를 수행하게 되는데, 이를 1xn과 nx1 Convolution으로 분해 가능
- Factorization을 사용하면, n x n개의 파라미터가 n+n개로 되어 큰 절감효과
- Inception module이 2종류에서 3종류로 늘어남
- 초반부의 Auxiliary classifier 제거 (효과 미미)
- 최종 단에 feature-map의 개수가 더 많아짐
- Convolution과 Pooling의 stride를 2로 변경
- 22-layer에서 42-layer로 깊어지고, 연산량이 2.5배 증가
GoogLeNet-V3
- RMSProp Optimizer 사용: 학습할 때 optimizer를 SGD에서 RMSProp로 변경
- RMSProp는 많이 변화한 변수는 최적값에 근접했을 것이라는 가정
- 업데이트 횟수에 따라 학습률을 조절하는 Adagrad에 지수 가중 이동 평균의 컨셉을 사용하여 최신 기울기들이 더 크게 반영되도록 한 것
- Label smoothing 적용: 레이블을 부드럽게 깎아서 일반화 성능을 높이고자 하는 것
- Hard label(One-hot encoded vector로 정답 인덱스는 1, 나머지는 0으로 구성)을 Soft label(라벨이 0과 1 사이의 값으로 구성)로 스무딩하는 것을 의미
- Batch Normalization 적용: 학습을 더 빨리 하기 위해서 또는 Local optimum 문제에 빠지는 가능성을 줄이기 위해서 사용
- 특정 Hidden Layer에 들어가기 전에 Batch Normalization Layer를 더해주어 input을 modify해준 뒤 새로운 값을 activation function으로 넣어주는 방식으로 사용
- 이때, 활성화 함수에 원래는 Wx+b 형태로 weight를 적용시키는데, Batch Normalization을 사용하고 싶을 경우 normalize 할 때 beta 값이 바이어스의 역할을 대체할 수 있기 때문에 b를 없애줌
- 결과적으로 Wx에 대해 Batch Normalization을 한 후, activation function을 적용
5. ResNet (2015)
paper: "Deep Residual Learning for Image Recognition"
의의: Residual Learning을 도입하여 Vanishing Gradient 문제를 해결하여 네트워크의 깊이를 늘리면서 안정적인 학습
- 네트워크가 깊어질수록 더 쉽게 학습할까?
- Convergence Problem: Gradient가 너무 작어지거나 커져 학습이 매우 느려지는 현상 발생(Gradient Vanishing/Exploding).
- 이는 학습 초기부터 convergence(수렴)를 방해한다.
- 이 문제는 normalized initialization과 intermediate normalization layer로 다뤄진다.
- -> Back Propagation과 함께 SGD(Stochastic gradient descent)로 수십층의 layer를 convergence 할 수 있게 됨
- Degradation Problem: Convergence가 가능해지고 나니, degradation 문제가 나타남
- network 깊이가 증가할수록 accuracy가 포화되고 그 이후로 빠르게 하락한다.
- 예상과 다르게 degradation은 overfitting에 의해 발생하는 문제가 아니었고, layer를 더 추가하면 training error가 높아진다.
- Convergence Problem: Gradient가 너무 작어지거나 커져 학습이 매우 느려지는 현상 발생(Gradient Vanishing/Exploding).
- 깊은 네트워크를 사용하면서 좋은 성능을 내는 방법
- 첫 번째는 얕은 네트워크에서 추가된 layer에 identity mapping(입력값과 출력값이 같은 형태)
- 두 번째는 네트워크 앞쪽 layer를 얕은 네트워크에서 학습된 layer를 사용하는 것
- 제안 구조
- 일반적인 딥러닝 네트워크는 쌓여진 layer들을 underlying mapping 하도록 (입력 x가 layer를 통과한 output이 목표값 y에 딱 맞도록) 학습
- 제안된 구조인 Deep Residual Learning은 residual(잔차, 입력과 출력의 차이)를 mapping 하도록 학습
- residual(잔차)가 0이 되도록 학습하여 identity mapping이 되도록
- residual이 0이 되도록 학습된 layer를 얕은 네트워크 뒤에 추가한다면 training error가 얕은 네트워크보다 작아지게 될 것
Residual(identity) mapping: shortcut connection(skip connection)
의의: 입력값을 layer들을 통과한 출력값에 더하며, 추가적인 파라미터가 없고 연산량 증가가 크지 않은 장점. 또한 end-to-end 학습이 가능
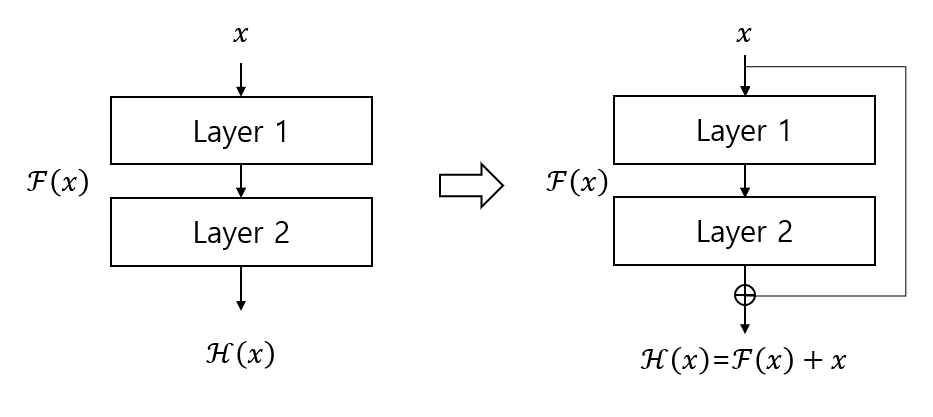
- 기존은 CNN은 입력 값 x를 타깃 값 y로 매핑하는 함수 H(x)를 얻는 것이 목적이으나, ResNet은 F(x) + x를 최소화하는 것을 목적으로.
- x는 현시점에서 변할 수 없는 값이므로 F(x)를 0에 가깝게 만드는 것이 목적이 되는 것입니다. F(x)가 0과 가까워질수록 출력과 입력이 모두 x와 가까워지며 F(x) = H(x) - x 이므로 F(x)를 0과 가깝게 한다는 말은 H(x) - x를 0과 가깝게 하는 말과 동일한 의미를 지닙니다(이를 identity mapping이라 함). 여기서 H(x) - x를 Residual이라고 함
- weight laeyr를 통과한 F(x)와 weight layer를 통과하지 않은 x의 합을 논문에서는 Residual Mapping이라고 하며, 위 그림의 구조를 Residual Block이라고 하고 이것이 쌓이면 Residual Network 즉, ResNet이라고 함
- Residual Mapping은 간단하지만 Overfitting, Gradient vanishing 문제가 해결되어 성능이 향상됨.
참고
- [Blog] [CNN Networks] 4. ResNet: https://velog.io/@woojinn8/CNN-Networks-4.-ResNet
- [Blog] Inception Module과 GoogLeNet: https://gaussian37.github.io/dl-concept-inception/
- [Blog] ResNet 구조 이해 및 구현: https://wjunsea.tistory.com/99