[논문 리뷰] NeRF in the Wild(NeRF-W): NeRFwithRealWorld + Embedding - Neural Radiance Fields for Unconstrained Photo Collections (CVPR 2021 Oral)
💡 💡 본 문서는 'Wild-GS: Real-Time Novel View Synthesis from Unconstrained Photo Collections (Arxiv 2024)' 논문을 정리해놓은 글이다.
해당 논문은 관광객이 찍은 데이터셋을 활용하여 3D Reconstruction을 진행하는 Task(unstructured tourist environments)를 해결하기 위한 논문이다. 이는 NeRF 기반이 아닌 Gaussian Splatting 을 활용하였으며, Hierarchical Appearance Modeling과 Depth Regularization을 진행한 것이 특징이니 참고하기 바란다.
- Project: https://www.lerf.io/
- Paper: https://arxiv.org/abs/2303.09553
- Github: https://github.com/kerrj/lerf
- Dataset: https://drive.google.com/drive/folders/1vh0mSl7v29yaGsxleadcj-LCZOE_WEWB
Abstract
기존의 NeRF는 static한 subjects에 대해서만 다루었다. 따라서 variable illumination or transient occluders와 같은 실제 현상을 다룬 사진에 대해서는 다루지 않았다. 따라서 unstructured image collections으로 부터 NeRF를 통해 3D Reconstruction을 적용해보겠다.
이 논문이 가지는 contribution 중 가장 메인이 되는 부분을 정리해보면 다음과 같다.
- Latent Appearance Modeling을 진행하여 출력의 Appearance 변화(조도)를 조절해보자
- Static한 네트워크와 Transient한 네트워크를 분리하여 Transient한 Object를 제거하자(+ Uncertainty)

Methods
Architecture
NeRF-W는 NeRF의 Network와 많은 차이를 가지고 있지 않다. input과 output을 기준으로 네트워크를 비교해본 결과, 색깔로 하이라이트해둔 부분이 같았으며, 그 외의 부분만 추가된 것을 확인할 수 있었다.
그 외의 부분인 Appearance Embedding과 MLP_3에 엮여있는 Transient Embedding, Uncertainty(β)에 대해서는 아래에서 차례대로 알아가보도록 하겠다.
Static Network
Static Network는 기존의 NeRF 모델에서 Appearance Embedding 부분만 추가로 넣어주었다.
Appearance Embedding은 mm.Embedding으로 생성된 Embedding Vector로, Random 초기화된 후 MLP를 통해 학습된다. 이는 이미지의 Embedding Vector이며, 추후 Appearance 조정을 위해 해당 Embedding Vector를 수정하며 Appearance 조정 가능하다(스타일 조정).
이때 Appearance는 학습 데이터셋에 대해서 학습했기에, 테스트시 타겟 이미지에 맞게 Embedding Vertor 내에서 유사한 벡터를 추출하여 사용한다.
Transient Network
Transient Network는 NeRF 모델의 3D shape 정보를 가지고 있는 MLP1 부분은 그래도 사용하되, MLP3를 추가로 두어 Transient Object(Occuluder)를 제거하도록 학습한다.
이때 Network의 Output으로 Uncertainty도 나오게 되는데, 이는 Loss Term으로만 학습된다. 이 역시도 color 로 pixel 값을 렌더링 하듯, uncertainty를 렌더링할 수 있는데 결과는 아래의 수식처럼 나타낼 수 있으며 추출된 결과는 (e) Uncertainty 와 같다.
Volume Rendering
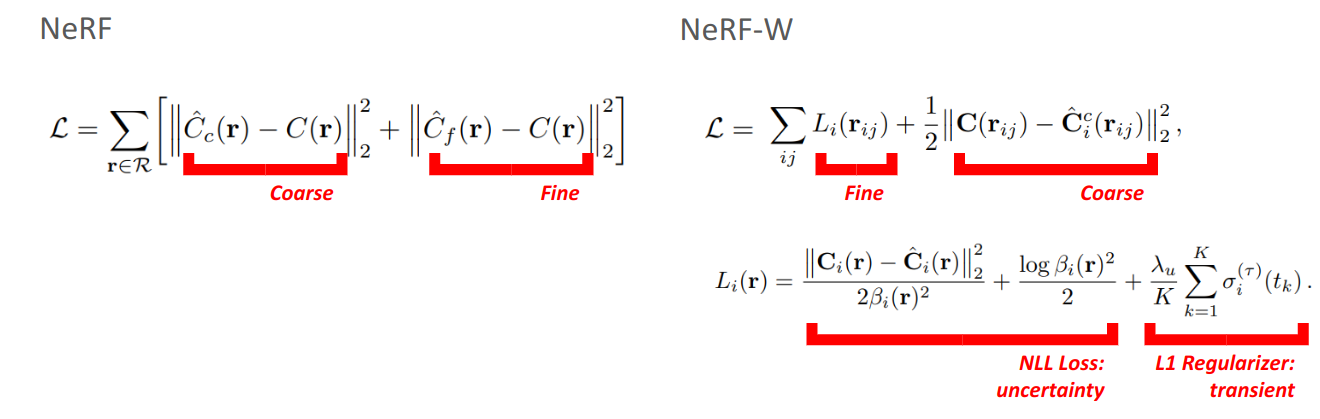
Optimization
Implementation Details
- COLMAP을 이용하여 Camera Pose 추정
- 총 300,000회 반복, batch size 2048, 8개 Nvidia V100 GPU 이용
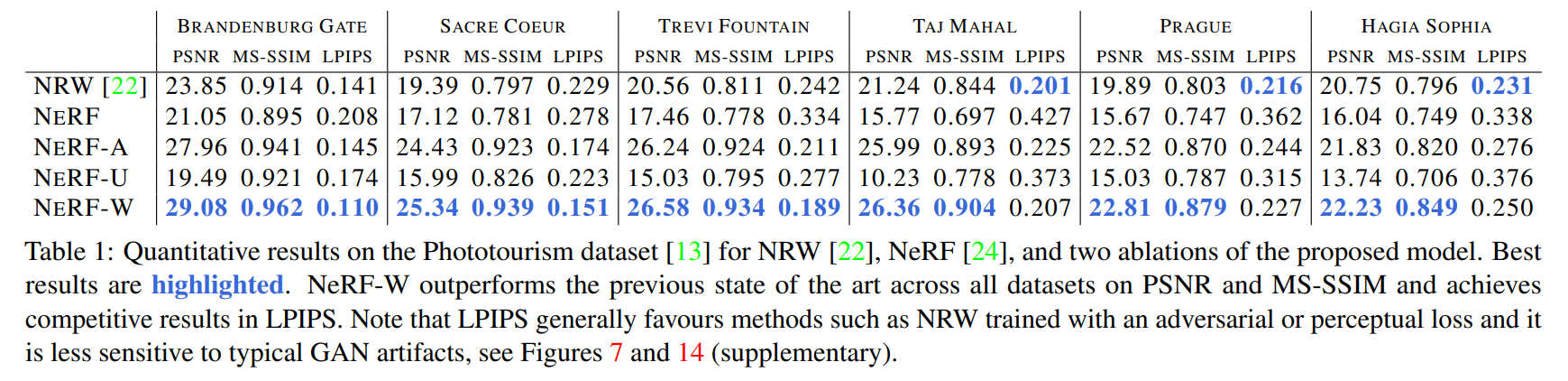
Experimental