[논문리뷰] DINO: Emerging Properties in Self-Supervised Vision Transformers (ICCV 2021)
💡 💡 본 문서는 'DINO: Emerging Properties in Self-Supervised Vision Transformers (ICCV 2021)' 논문을 정리해놓은 글이다.
해당 논문은 DINO라는 self-distillation 구조의 자기지도학습 방법론을 제안하며, 동시에 self-supervised learning과 ViT가 결합되며 발생하는 특성들에 대한 분석과 흥미로운 실험 결과를 논문에서 밝히고 있다. 특히 self-supervised ViT가 segmentation mask에 대한 정보를 갖고 있다는 특성이 굉장히 재미있었고, 기존의 supervised ViT 같은 경우에는 object boundary에 대한 정보를 직접적으로 얻을 수 없고 attention flow와 같은 추가적인 조작 방법이 들어가야 하지만 self-supervised ViT는 마지막 레이어의 attention head에서 직접적으로 해당 정보에 접근이 가능하다는 점(다만 이 경우에는 왜 그렇게 되는지에 대한 궁금증이 조금 남았던 것 같습니다)도 재미있게 읽은 논문이니 참고하기 바란다.
- Project: https://arxiv.org/abs/2104.14294
- Paper: https://arxiv.org/abs/2303.09553
- Github: https://github.com/facebookresearch/dino
- Video: https://www.youtube.com/watch?v=h3ij3F3cPIk
Abstract
self-sup 방법론을 ViT에 적용해서 잘 나오는 걸 넘어서, 다음과 같은 발견을 했다.
- self-supervised ViT features contain explicit information about the semantic segmentation of an image (supervised ViT나 convolutional nertworks(convnets)에서는 발생하지 X)
- these features are also excellent -NN classifiers, reaching 78.3% top-1 on ImageNet with a small ViT.
- momentum encoder, multi-crop training, and the use of small patches with ViTs 역시 중요함을 강조함.
위의 finding을 DINO (self-distillation with no labels)라는 simple self-supervised method를 통해 implement함. ViT-Base 구조로 Top-1 linear probing accuracy를 80.1% 달성하면서 DINO와 ViT 간 시너지를 보여줌.
이 논문이 가지는 contribution 중 가장 메인이 되는 부분을 정리해보면 다음과 같다.
Introduction
최근 Transformer는 이미지 인식 분야에서 convnet (convolutional neural network)의 대안으로 떠오르고 있다. NLP에서 영감을 받아 많은 양의 데이터로 사전 학습한 뒤 목표 데이터셋에 대하여 finetuning하는 학습 전략을 사용한다. ViT는 경쟁력 있지만 convnet을 뛰어넘는 이점이 아직 없다. 계산 비용이 더 요구되며 더 많은 학습 데이터과 필요하고 feature들이 고유한 속성을 나타내지 않는다.
본 논문에서는 vision 분야에서 Transformer의 조용한 성공이 사전 학습에서 supervision을 사용하여 설명될 수 있는지 질문한다. 저자들의 동기는 NLP에서 Transformer의 성공을 위한 주요 요소 중 하나가 BERT의 close procedure 또는 GPT의 언어 모델링 형태로 self-supervised pretraining을 사용했다는 것이다. 이러한 self-supervised pretraining의 목적 함수는 문장의 단어를 사용하여 문장당 단일 레이블을 예측하는 지도 학습의 목적 함수보다 더 풍부한 학습 신호를 제공하는 pretext task를 생성한다. 마찬가지로 이미지에서 supervision은 종종 이미지에 포함된 풍부한 시각적 정보를 미리 정의된 수천 개의 카테고리 집합에서 선택된 단일 개념으로 축소한다.
NLP에서 사용하는 self-supervised pretext task가 텍스트에 한정되지만 다양한 self-supervised 방법들은 이미지에서 잠재력이 있다는 것을 보여주었다. 이러한 방법들은 일반적으로 유사한 구조를 공유하지만 자명해(collapse)를 피하거나 성능을 향상시키기 위해 설계된 다른 구성 요소를 사용한다. 본 논문은 이러한 방법에서 영감을 받아 ViT feature들에서 self-supervised pretraining의 영향을 연구하였다.
특히 흥미롭게도 저자들은 supervised ViT나 convnet에서 나타나지 않는 몇 가지 흥미로운 속성을 확인했다.

- Self-supervised ViT feature들은 위 그림과 같이 장면 레이아웃, 특히 객체 경계를 명시적으로 포함한다. 이 정보는 마지막 블록의 Self-attention 모듈에서 직접 접근할 수 있다.
- Self-supervised ViT feature들은 finetuning, linear classifier, data augmentation 없이 기본 k-NN에서 특히 잘 수행되어 ImageNet에서 78.3%의 top-1 accuracy를 달성하였다.
Self-supervised 방법에서는 segmentation mask의 출현이 공통 속성으로 나타나는 것으로 보인다. 그러나 k-NN에서 우수한 성능은 momentum encoder와 multi-crop augmentation과 같은 특정 구성 요소를 결합할 때만 나타난다. 또 다른 발견 중 하나는 ViT와 결과 feature의 품질을 개선하기 위해 작은 패치를 사용하는 것이 중요하다는 것이다.
이런 구성 요소의 중요성에 대한 발견은 라벨이 없는 knowledge distillation (with no label)의 한 형태로 해석될 수 있는 간단한 self-supervised 방법을 설계하도록 이끌었다. 그 결과로 설계된 프레임워크인 DINO는 표준 cross-entropy loss를 사용하여 momentum encoder로 구축된 teacher network의 출력을 직접 예측함으로써 self-supervised training을 단순화한다. 흥미롭게도, 이 방법은 collapse를 피하기 위해 teacher output의 centering과 sharpening만으로 작동할 수 있다. 특히 중요한 점은 프레임워크가 유연하고 아키텍처를 수정하거나 내부 정규화를 적용할 필요 없이 convnet과 ViT 모두에서 작동한다는 것이다.
본 논문에서는 작은 패치를 사용하는 ViT-Base로 80.1%의 top-1 accuracy로 ImageNet linear classification 벤치마크에서 이전의 self-supervised feature들을 능가함으로써 DINO와 ViT간의 시너지 효과를 추가로 검증한다. 또한 DINO를 state-of-the-art ResNet-50 아키텍처에 사용하여 DINO가 convnet과 함께 작동함을 확인한다. 마지막으로 계산 및 메모리 용량이 제한된 경우 ViT와 함께 DINO를 사용하는 다양한 시나리오에 대해 논의한다. 특히, ViT로 DINO를 교육하는 데 3일 동안 단 2개의 8-GPU 서버만 있으면 ImageNet linear classification 벤치마크에서 76.1%를 달성할 수 있다고 한다.
Approach
1. SSL with Knowledge Distillation
DINO는 최근 self-supervised 방법들과 전체 구조가 같지만 knowledge distillation과 유사하며 knowledge distillation 관점에서 DINO를 제시한다. DINO는 다음 그림과 같이 나타낼 수 있다.
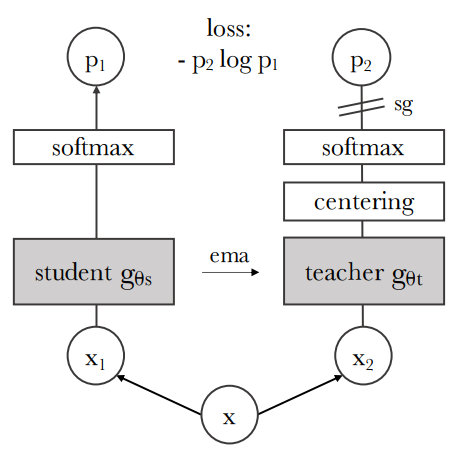
DINO의 알고리즘 pseudo-code는 다음과 같다.

Knowledge distillation는 student network 를 학습할 때 출력을 주어진 teacher network 와 일치시키는 학습 패러다임이다. 이미지 가 주어졌을 때 두 신경망 모두 차원의 확률 분포 와 Pt를 출력한다. 확률 분포 는 네트워크 의 출력을 softmax function으로 정규화하여 얻는다.
와 는 temperature parameter이며 출력 분포의 뾰족한 정도를 조절한다. 고정된 teacher network gθt가 주어졌을 때 student network의 파라미터 에 대한 cross-entropy loss를 최소화하여 두 신경망의 출력 분포를 일치시킨다.
여기서 이다.
다음은 어떻게 저자들이 위 방법을 self-supervised learning에 적용하였는 지에 대한 디테일한 부분이다. 먼저, 저자들은 multi-crop strategy로 이미지의 다양한 distorted view나 crop을 구성하였다. 보다 정확하게는 주어진 이미지에서 서로 다른 view의 set V를 생성한다. 이 set은 두 global view x1g와 x2g와 작은 해상도에서의 몇몇 local view를 포함한다. 모든 crop 이미지가 student를 통과할 수 있지만 teacher는 global view만 통과할 수 있으며, 이를 통해 “local-to-global” 대응을 장려한다. 따라서 다음 loss를 최소화한다.
이 loss는 범용적이고 2개의 view뿐만 아니라 여러 개의 view에 대하여 사용할 수 있다. 저자들은 multi-crop 표준 설정대로 원본 이미지의 넓은 영역을 포함하는 해상도의 global view 2개와 원본 이미지의 좁은 영역을 포함하는 해상도의 local view 여러개를 사용한다. 이를 DINO의 기본 설정으로 한다.
두 신경망 모두 같은 아키텍처 를 사용하며 서로 다른 파라미터 와 θt를 가진다. θs는 위 loss 식을 SGD로 최소화하여 학습시킨다.
Teacher network
Knowledge distillation과 다르게 사전 지식으로 teacher network gθt를 가지지 않으므로, teacher network를 student network의 이전 iteration으로 구축한다. 저자들은 여러 업데이트 규칙을 teacher에 실험하였으며, teacher network를 epoch 동안 freeze하는 것이 상당히 좋은 결과를 보였고 student의 가중치를 teacher로 복사하는 것은 수렴하지 못하였다고 한다. Student의 가중치에 exponential moving average (EMA)를 사용하는 momentum encoder가 특히 프레임워크에 잘 맞았다고 한다.
업데이트 규칙은
이며, 학습 중에 는 0.996에서 1로 증가하는 cosine schedule을 따른다. 원래 momentum encoder가 contrastive learning의 큐에서 사용되었지만, DINO에는 큐나 contrastive loss가 없으므로 역할이 다르고 self-training에 사용하는 mean teacher의 역할을 한다. 학습 중에는 teacher가 student보다 더 성능이 좋으며, teacher가 target feature들을 고품질로 제공하여 student의 학습을 guide한다.
Network architecture
신경망 g는 ViT나 ResNet backbone f와 projection head h로 이루어져 있다. (g=h∘f) Projection head는 layer 3개의 MLP, l2 정규화, 가중치가 정규화된 FC layer로 구성된다. 저자들은 다른 projection head들도 실험해보았지만 앞서 설명한 디자인이 DINO에 가장 적합하였다. 특히 흥미로운 점은 표준 convnet과 달리 ViT 아키텍처는 기본적으로 batch 정규화(BN)를 사용하지 않는다는 것이다. 따라서 ViT에 DINO를 적용할 때는 projection head에서 BN을 제거하여 전체 시스템에 BN이 없도록 하였다.
Avoiding collapse
여러 self-supervised 방법이 contrastive loss, clustering constraints, predictor, BN 등의 다양한 방법으로 collapse를 피하려고 한다. DINO는 여러 정규화로 안정화될 수 있지만 collapse를 피하기 위해 momentum teacher output의 centering 및 sharpening만으로 작동할 수도 있다.
Centering은 한 차원이 지배하는 것을 방지하지만 uniform 분포로의 collapse를 조장하는 반면, sharpening은 반대 효과를 낸다. 두 연산을 모두 적용하여 collpase를 피하기에 충분하도록 각 효과의 균형을 맞춘다. Collapse를 피하기 위하여 centering을 사용하면 batch에 대한 의존도를 낮추기 위해 안정성을 낮아진다. 이는 centering 연산이 1차 batch 통계에만 의존하며 teacher에 bias 항을 추가하는 것으로 해석할 수 있다.
중심 c는 EMA로 업데이트되며 batch size가 다르더라도 잘 적용된다.
여기서 은 rate parameter이고 는 batch size이다. Sharpening은 teacher softmax normalization의 를 낮은 값으로 두는 것으로 할 수 있다.
2. Implementation and evaluation protocols
Vision Transformer
저자들은 DeiT의 implementation을 사용하였다. 본 논문에서 사용한 모델들의 설정은 다음 표와 같다.
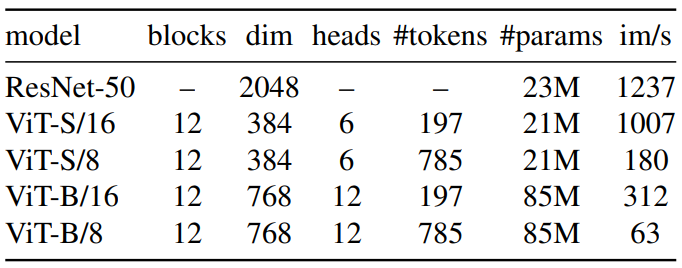
ViT 아키텍처는 겹치치 않는 연속적인 의 이미지 패치를 입력으로 받는다. 본 논문에서는 일반적으로 (“/16”)이나 (“/8”)을 사용하였다. 이 패치들은 linear layer을 통과하여 임베딩이 된다.
저자들은 추가 학습가능한 토큰을 시퀀스에 넣어 전체 시퀀스의 정보를 집계하도록 하였으며, 출력에 projection head h를 연결하였다. 이 토큰은 어떠한 레이블이나 supervision에 연결되지는 않지만 기존 연구들과의 일관성을 위해 클래스 토큰 [CLS]이라 부른다. 패치 토큰과 [CLS] 토큰은 pre-norm layer normalization을 가진 표준 Transformer network에 입력된다.
Transformer는 self-attention과 feed-forward layer의 시퀀스이며 skip connection으로 병렬화된다. Self-attention layer는 attention mechanism으로 다른 토큰 표현을 보고 각 토큰 표현들을 업데이트한다.
Implementation details
- 데이터셋: ImageNet 데이터셋에 레이블 없이 사전 학습
- batch size 1024, adamw optimizer, 16 GPUs
- learning rate는 처음 10 epoch만 0.005×batchsize/256까지 warmup 후 cosine schedule로 decay
- weight decay: cosine schedule로 0.04에서 0.4
- τs=0.1, τt는 0.04에서 0.07로 초반 30 epoch동안 linear-warmup
- BYOL의 data augmentation (color jittering, Gaussian blur and solarization)과 multi-crop을 사용
Evaluation protocols
Self-supervised learning을 평가하는 표준 프로토콜은 고정된 feature들을 linear classifer로 학습시키거나 feature을 downstream task에서 finetune하는 것이다.
Linear evaluation을 위해서 random resize crop과 horizontal flips augmentation을 학습에 사용하고 central crop에 대한 accuracy를 측정하였다. Finetuning evaluation을 위해서 사전 학습된 가중치로 신경망을 초기화하고 학습 단계에서 적응시켰다.
한편, 두 evaluation 모두 hyperparameter에 민감하므로 learning rate를 바꾸면 실행할 때마다 정확도가 크게 변하는 것을 발견하였다고 한다. 따라서 저자들은 feature들의 품질을 간단한 가중치 k-NN classifer로 측정하였다. 사전 학습된 모델을 고정시키고 feature를 계산한 뒤 저장한다. 그런 다음 k-NN classifer는 이미지의 feature을 레이블에 투표하는 k개의 가장 가까운 저장된 feature과 일치시킨다.
저자들은 다양한 k에 대하여 실험을 한 결과 20으로 두는 것이 전체적으로 성능이 제일 좋았다고 한다. 이 evaluation 방법은 추가 hyperparameter tuning이나 data augmentation이 필요 없으며 하위 데이터셋에 대하여 1번만 실행하면 되기 때문에 feautre evaluation을 굉장히 간단하게 만든다.
Main Results
1. Comparing with SSL frameworks on ImageNet
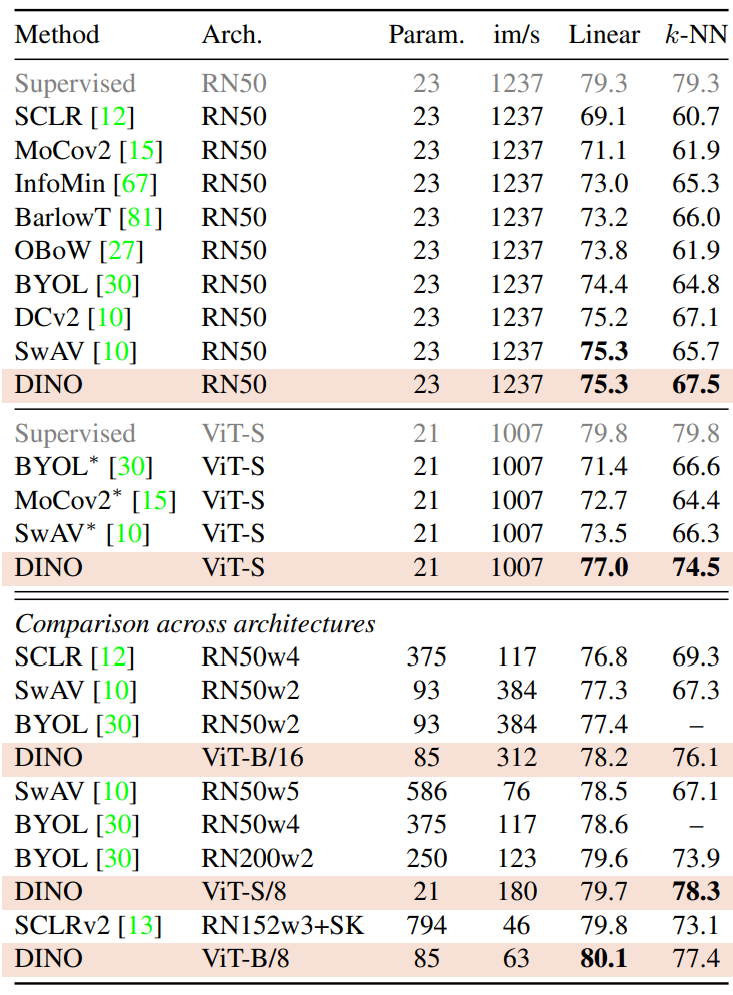
다음은 다양한 self-supervised 방법에 대한 ImageNet에서의 linear과 k-NN evaluation의 top-1 accuracy이다. Throughput (im/s)은 NVIDIA V100 GPU에서 한 번에 128개의 샘플을 출력할 때 측정한 값이다.
2. Properties of ViT trained with SSL
Nearest neighbor retrieval with DINO ViT
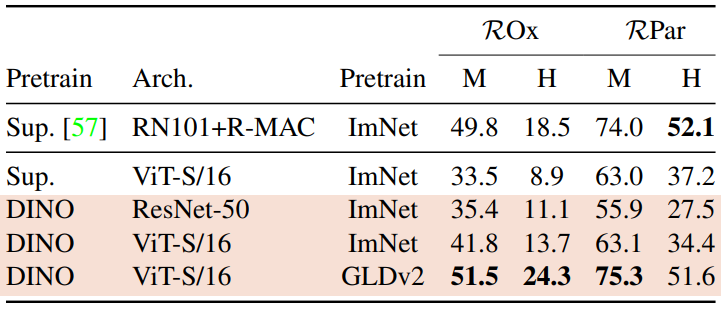
다음은 이미지 retrieval에 대한 성능 비교이다. Supervision(Sup.)이나 DINO로 ImageNet이나 Google Landmarks v2(GLDv2) 데이터셋에서 사전 학습된 feature의 retrieval 성능을 비교한다.
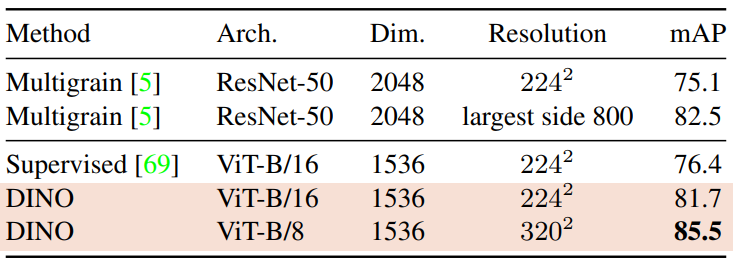
다음은 copy detection task에 대한 성능 비교이다. INRIA Copydays 데이터셋의 “강한” 부분집합에 대하여 mean average precision (mAP)를 측정하였다. Copy detection task은 blur, insertions, print and scan 등으로 왜곡된 이미지를 인식하는 task이다.
Discovering the semantic layout of scenes
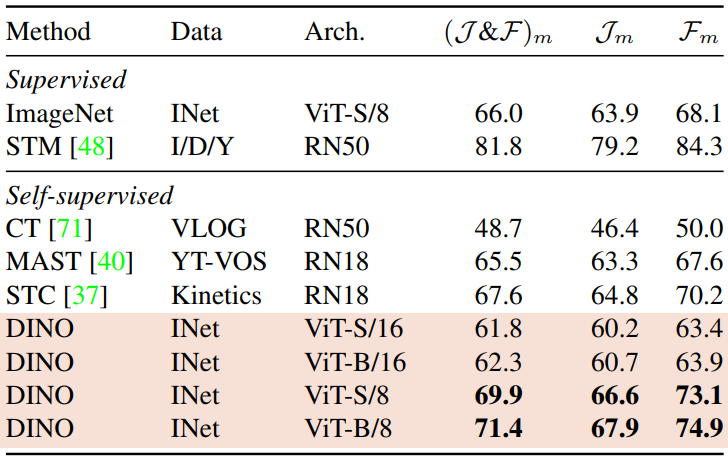
아래 표는 DAVIS-2017 video instance segmentation 벤치마크에서의 출력 패치 토큰을 평가한 것이다. Jm은 mean region similarity이고 Fm은 mean contour-based accuracy이다. 이미지 해상도는 480p이다.
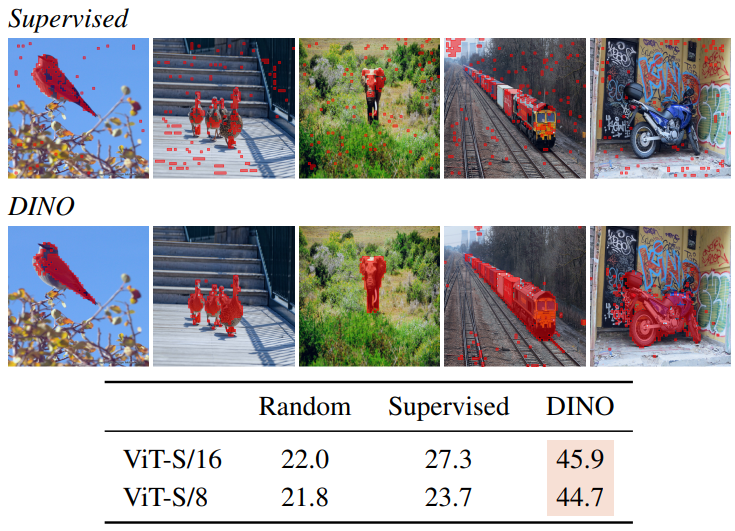
다음은 서로 다른 head들이 다른 semantic region에 참여하는 것을 보여주는 그림이다.

다음은 supervised와 DINO의 segmentation 결과이다. Self-attention map에 임계값을 주어 mask를 얻어 시각화한 것이다.
Transfer learning on downstream tasks
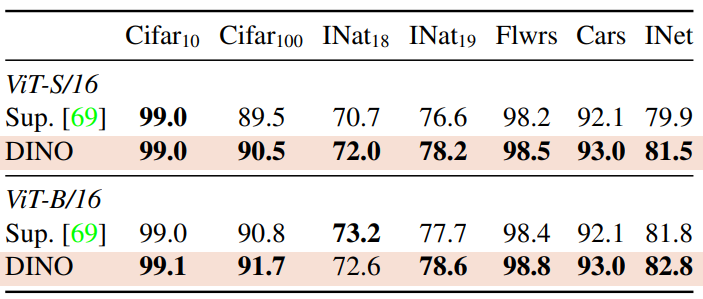
다음은 여러 하위 task에서 DINO로 사전 학습된 feature의 품질을 평가한 표이다.
Ablation Study of DINO
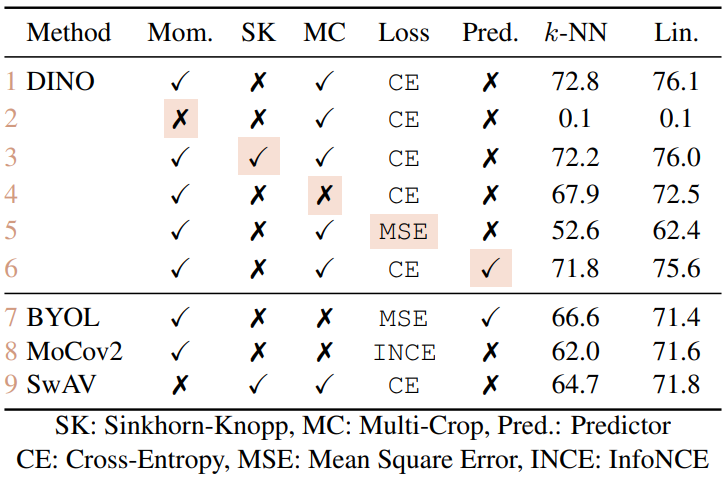
1. Importance of the Different Components
다음은 요소를 추가하거나 제거한 변형 모델의 성능을 비교한 것이다.
다음은 다양한 패치 크기에서 ViT-S 모델의 k-NN classification 성능을 비교한 것이다.

2. Impact of the choice of Teacher Network
다음은 ImageNet에 대한 k-NN classifer로 측정한 top-1 accuracy이다.
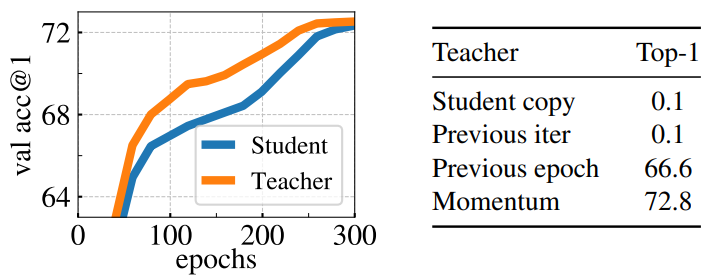
왼쪽은 학습 중의 momentum teacher과 student의 성능을 비교한 것이다. 오른쪽은 다양한 teacher network에 대한 성능 비교이다.
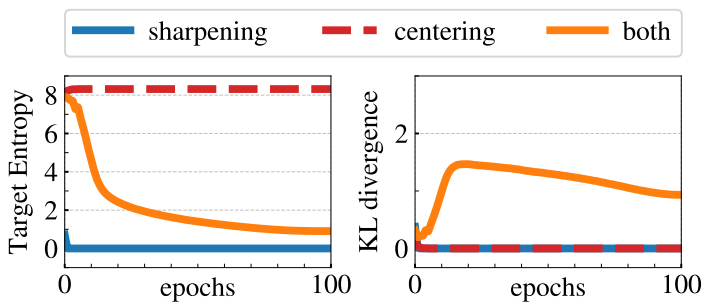
3. Avoiding collapse
다음은 centering과 sharpening이 collapse를 피하는 데 수행하는 역할을 연구한 것이다.
Collapse에는 두 가지 형태가 있다. 하나는 입력을 무시하고 모델의 출력이 모든 차원에서 균일한 것이고, 다른 하나는 한 차원이 지배적인 것이다. Centering은 한 차원이 지배적인 collapse를 피하지만 균일한 출력을 유도하며, sharpening은 반대 효과가 나타난다. 이러한 특성은 cross-entropy H를 entropy h와 KL divergence DKL로 나누어 보면 알 수 있다.
H(Pt,Ps)=h(Pt)+DKL(Pt|Ps)
KL divergence가 0이라는 것은 출력이 상수라는 것을 의미하며 이는 collapse이다. 다음 표는 centering과 sharpening을 학습에 사용할 때와 사용하지 않을 때의 entropy와 KL divergence를 측정한 것이다.
4. Compute requirements
다음 표는 2개의 8-GPU machine에서 ViT-S/16 DINO을 실행하는 데 필요한 총 시간과 GPU당 메모리를 보여준다.
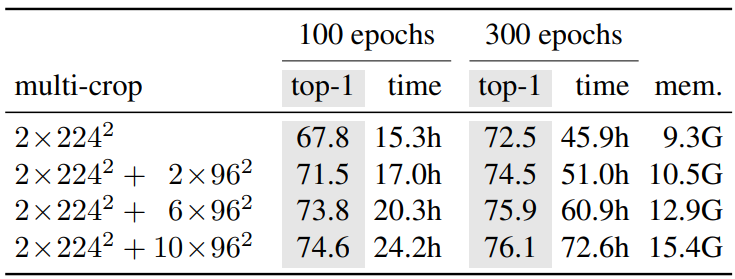
Multi-crop이 정확도와 실행시간 tradeoff를 개선하는 것을 보여준다.
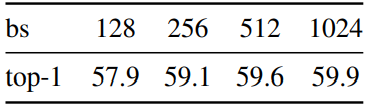
5. Training with small batches
다음은 batch size에 대한 효과를 나타낸 표이다.