Study: Artificial Intelligence(AI)/AI: 3D Vision
[논문리뷰] PETR : Position Embedding Transformation for Multi-View 3D Object Detection (ECCV 2022)
DrawingProcess
2024. 7. 12. 05:39
반응형
💡 본 문서는 'PETR : Position Embedding Transformation for Multi-View 3D Object Detection (ECCV 2022)' 논문을 정리해놓은 글입니다.
해당 논문은 CLIP 같은 멀티모달 모델의 language embedding을 NeRF 안에 집어넣어 NeRF를 Multi Modal로 확장 가능성을 보여준 논문이니 참고하시기 바랍니다.
- Paper: https://arxiv.org/abs/2203.05625
- Github: https://github.com/megvii-research/PETR
Contribution

- DETR 계열의 Detection 모델들이 좋은 성능을 보여주고 있음
- DETR3D 는 3D Object Detection을 위한 모델인데, 2D-3D Transformation 과정에서 문제 발생
- 1. Reference Point 의 예측 좌표가 정확하지 못함
- 2. Projection된 이미지 Feature만 보기 때문에, Global Representation수행이 힘듦
- 3D 좌표를 이용한 Position Embedding Transformation 제안
- (a) DETR은 query와 2D Positioning Embedding (PE)가 따로 들어감.
- (b) Query로 부터 만들어진 reference point를 이미지 feature에 투영시켜 feature를 sampling.
- (c) 2D feature 와 3D PE를 함께 encoding 하여 3D aware feature 를 만들고, query와 decoding.
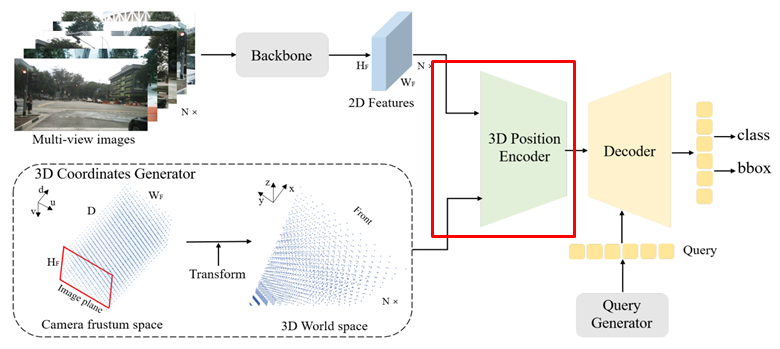
PETR overall Architecture

- Multi-view 이미지를 Backbone을 통해 2D Feature 추출
- 3D Meshigrid 형태의 Camera Frustum Sace 생성
- Frustum 을 이용하여 3D World Space Coordinate 로 변환
- 3D Position Encoder에서 3D Position Aware Feature 추출
- Object Query 와 Cross-Attention
- 최종 결과(3D box + class) 예측
1. Multi-view 이미지를 Backbone을 통해 2D Feature 추출 (ex, resnet50)
2. 3D Meshigrid 형태의 Camera Frustum Space 생성
이미지로부터 Frustum 생성

- 이미지 Coordinate 에 Depth 𝑑_𝑗 를 추가하여 Frustum 𝑝_𝑗^𝑚 을 만듦
- 𝑢_𝑗, 𝑣_𝑗 는 𝑑_𝑗에 해당하는 이미지 좌표를 뜻함
- Frustum은 각 이미지에서의 좌표값을 가지고 있음

3차원 좌표에서 Muti-view에 대한 Frustum을 표현하기 위해선 3D World Space로 변환을 해 주어야 함
- Frustum이 가지고 있는 이미지 좌표값으로 3차원에 표현하기엔 왜곡이 있기 때문에, 3D World 좌표로 변환 필요
3. Frustum 을 이용하여 3D World Space Coordinate 로 변환

- Frustum 에 변환 행렬을 곱하여 x,y,z 3D World 좌표로 변환 후 [-1, 1]로 Normalize
- 𝐾_𝑖 - 3D에서 i번째 카메라 Frustum으로 변환
- 𝑥_𝑚𝑖𝑛, 𝑥_𝑚𝑎𝑥, 𝑦_𝑚𝑖𝑛, 𝑦_𝑚𝑎𝑥 : 3D 에서 표현하고자 하는 x,y 최소/최대 값

4. 3D Position Encoder에서 3D position aware feature 추출
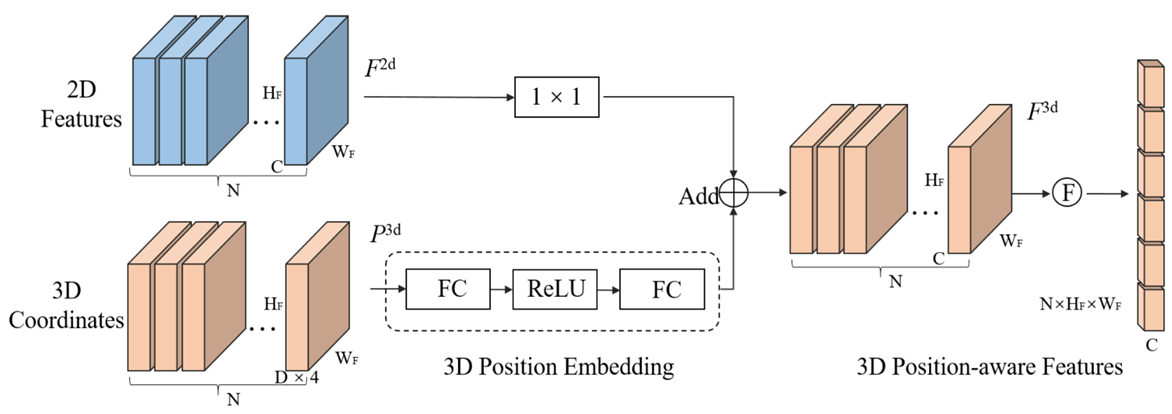
- 2D Feature 에 [1x1 Conv] 을 통해 인코딩
- 3D Coordinate 에 [FC-ReLU-FC] 을 통해 인코딩
- 둘을 더하여 3D position 이 반영된 feature를 추출 후 flatten
5. Object Query 와 Cross-Attention 변환
- Query Generator - Object Query 생성
- 먼저, 3D 에서의 Learnable Anchor Points 을 Uniform 하게 생성
- Anchor 의 3D 좌표 작은 MLP를 통해 Object Query 생성
- 생성된 Query 와 3D-aware feature 와 Cross Attention
6. 생성된 Query와 3D Position-aware Feature를 key, value로 하여 DETR3D Decoder에 넣어 최종 3D box 예측
Positional Embedding Analysis
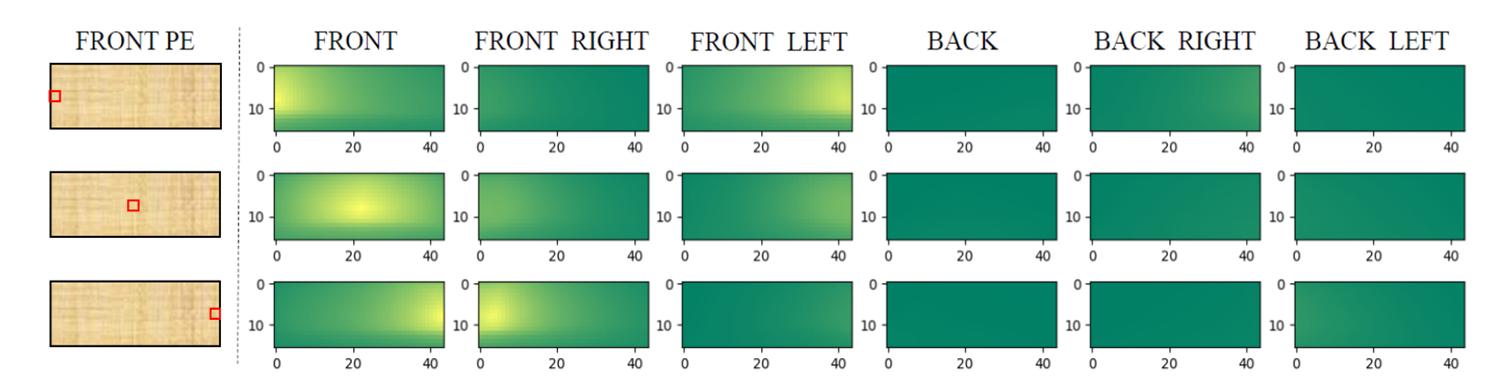
빨간 점은 random 하게 sampling 한 점이고, 오른쪽 여섯장의 이미지는 sampling 된 점과의 similiarity를 분석한 결과. 노란색일수록 높은 similarity를 보여줌
- Front view 의 random 한 좌표를 각 다른 view 에서 similarity 분석
- 가까운 영역에서 similarity 가 높음
- Positional Embedding 이 다른 view끼리의 correlation 을 만듦
- 제안하는 Positional Embedding 은 좋은 성능을 낼 수 있음을 뜻함
Experiments
해당 모델은 nuscens dataset에서 성능을 검증함. 6장의 multi-view image를 인풋으로 받아 3차원 물체의 위치 및 종류를 검출하는 Task 수행.
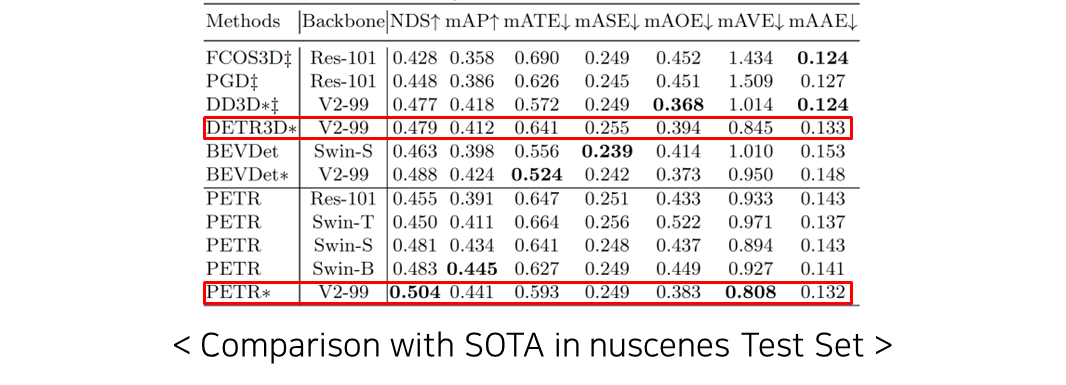
- ∗ - trained with external data, ‡ - test time augmentation
- PETR은 기존 SOTA의 모델들보다 좋은 NDS, mAP, mAVE에서 가장 좋은 성능을 보여줌
- DETR3D보다 좋은 성능을 보여줌으로써 제안하는 Positioning Embedding의 효과를 입증
Ablation Study
2D와 MV를 사용할때보다 3D만을 사용할때 더 확실히 더 좋은 성능을 보이며, 모두 사용하면 가장 좋은 성능을 볼 수 있음
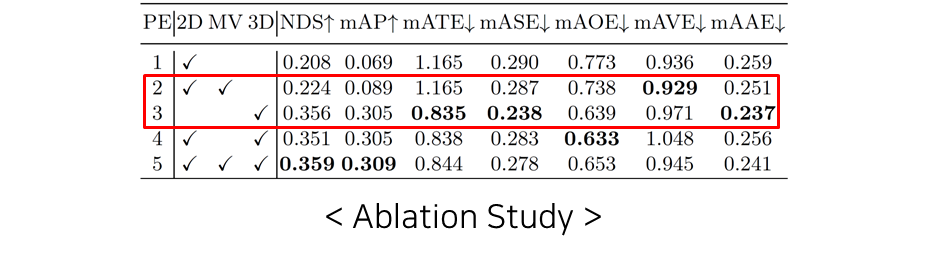
- 2D – 2D Positioning Embedding
- MV – Multi-view Position Embedding
- 3D – 3D Positioning Embedding

- 1x1 conv를 사용하는 것은 MLP를 사용하는 것과 같은 효과를 보여줌
- 3x3 conv는 주변에 위치한 coordinate 정보와 관련된 feature를 aggregate하고자 함인데, 이때의 결과는 좋지 못함
- 이는 semantic한 정보가 position 정보를 대표하는데 크게 중요하지 않고, 각 개별적 좌표값이 대표되는 것이 중요한 것을 뜻함.
반응형